Search Logged Models
This guide will walk you through how to search for logged models in MLflow using both the MLflow UI and Python API. This resource will be valuable if you're interested in querying specific models based on their metrics, params, tags, or model metadata.
MLflow's model search functionality allows you to leverage SQL-like syntax to filter your logged models based on a variety of conditions. While the OR keyword is not supported, the search functionality is powerful enough to handle complex queries for model discovery and comparison.
Search Logged Models Overview
When working with MLflow in production environments, you'll often have hundreds or thousands of logged models across different experiments. The search_logged_models API helps you find specific models based on their performance metrics, parameters, tags, and other attributes - making model selection and comparison much more efficient.
Looking for guidance on searching over Runs? See the Search Runs documentation.
Create Example Logged Models
First, let's create some example logged models to demonstrate the search functionality. This documentation is based on models created with the below script. If you don't want to interactively explore this on your machine, skip this section.
Before running the script, let's start the MLflow UI on a local host:
mlflow ui
Visit http://localhost:5000/ in your web browser. Let's create some example models:
import mlflow
import mlflow.sklearn
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from mlflow.models import infer_signature
import warnings
# Suppress the MLflow model config warning if present
warnings.filterwarnings("ignore", message=".*Failed to log model config as params.*")
mlflow.set_experiment("model-search-guide")
# Model configurations
model_configs = [
{"model_type": "RandomForest", "n_estimators": 100, "max_depth": 10},
{"model_type": "RandomForest", "n_estimators": 200, "max_depth": 20},
{"model_type": "LogisticRegression", "C": 1.0, "solver": "lbfgs"},
{"model_type": "LogisticRegression", "C": 0.1, "solver": "saga"},
{"model_type": "SVM", "kernel": "rbf", "C": 1.0},
{"model_type": "SVM", "kernel": "linear", "C": 0.5},
]
# Performance metrics (simulated)
accuracy_scores = [0.92, 0.94, 0.88, 0.86, 0.90, 0.87]
precision_scores = [0.91, 0.93, 0.87, 0.85, 0.89, 0.86]
recall_scores = [0.93, 0.95, 0.89, 0.87, 0.91, 0.88]
f1_scores = [0.92, 0.94, 0.88, 0.86, 0.90, 0.87]
# Model metadata
versions = ["v1.0", "v1.1", "v1.0", "v2.0", "v1.0", "v1.1"]
environments = [
"production",
"staging",
"production",
"development",
"staging",
"production",
]
frameworks = ["sklearn", "sklearn", "sklearn", "sklearn", "sklearn", "sklearn"]
# Create dummy training data
X_train = np.random.rand(100, 10)
y_train = np.random.randint(0, 2, 100)
# Create input example for model signature
input_example = pd.DataFrame(X_train[:5], columns=[f"feature_{i}" for i in range(10)])
for i, config in enumerate(model_configs):
with mlflow.start_run():
# Create and train model based on type
if config["model_type"] == "RandomForest":
model = RandomForestClassifier(
n_estimators=config["n_estimators"],
max_depth=config["max_depth"],
random_state=42,
)
mlflow.log_param("n_estimators", config["n_estimators"])
mlflow.log_param("max_depth", config["max_depth"])
elif config["model_type"] == "LogisticRegression":
model = LogisticRegression(
C=config["C"],
solver=config["solver"],
random_state=42,
max_iter=1000, # Increase iterations for convergence
)
mlflow.log_param("C", config["C"])
mlflow.log_param("solver", config["solver"])
else: # SVM
model = SVC(
kernel=config["kernel"],
C=config["C"],
random_state=42,
probability=True, # Enable probability estimates
)
mlflow.log_param("kernel", config["kernel"])
mlflow.log_param("C", config["C"])
# Log common parameters
mlflow.log_param("model_type", config["model_type"])
# Fit model
model.fit(X_train, y_train)
# Get predictions for signature
predictions = model.predict(X_train[:5])
# Create model signature
signature = infer_signature(X_train[:5], predictions)
# Log metrics
mlflow.log_metric("accuracy", accuracy_scores[i])
mlflow.log_metric("precision", precision_scores[i])
mlflow.log_metric("recall", recall_scores[i])
mlflow.log_metric("f1_score", f1_scores[i])
# Log tags
mlflow.set_tag("version", versions[i])
mlflow.set_tag("environment", environments[i])
mlflow.set_tag("framework", frameworks[i])
# Log the model with signature and input example
model_name = f"{config['model_type']}_model_{i}"
mlflow.sklearn.log_model(
model,
name=model_name,
signature=signature,
input_example=input_example,
registered_model_name=f"SearchGuide{config['model_type']}",
)
After running this script, you should have 6 different models logged across your experiments, each with different parameters, metrics, and tags.
Note: You may see a warning about "Failed to log model config as params" - this is a known MLflow internal warning that can be safely ignored. The models and their parameters are still logged correctly.
Search Query Syntax
The search_logged_models API uses a SQL-like Domain Specific Language (DSL) for querying logged models. While inspired by SQL, it has some specific limitations and features tailored for model search.
Visual Representation of Search Components:
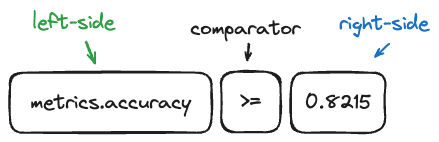
Key Differences from search_runs:
- Default Entity: When no prefix is specified, the field is treated as an attribute (not a metric)
- Supported Prefixes:
metrics.,params., or no prefix for attributes - Dataset-Aware Metrics: You can filter metrics based on specific datasets
- No Tag Support: Unlike
search_runs, thesearch_logged_modelsAPI does not support filtering by tags
Syntax Rules:
Left Side (Field) Syntax:
- Fields without special characters can be referenced directly (e.g.,
creation_time) - Use backticks for fields with special characters (e.g.,
metrics.`f1-score`) - Double quotes are also acceptable (e.g.,
metrics."f1 score")
Right Side (Value) Syntax:
- String values must be enclosed in single quotes (e.g.,
params.model_type = 'RandomForest') - Numeric values for metrics don't need quotes (e.g.,
metrics.accuracy > 0.9) - All non-metric values must be quoted, even if numeric
- For string attributes like
name, only=,!=,IN, andNOT INcomparators are supported (noLIKEorILIKE)
Example Queries
Let's explore different ways to search for logged models using various filter criteria.
1 - Searching By Metrics
Metrics represent model performance measurements. When searching by metrics, use the metrics. prefix:
import mlflow
# Find high-performing models
high_accuracy_models = mlflow.search_logged_models(
experiment_ids=["1"], # Replace with your experiment ID
filter_string="metrics.accuracy > 0.9",
)
# Multiple metric conditions
balanced_models = mlflow.search_logged_models(
experiment_ids=["1"],
filter_string="metrics.precision > 0.88 AND metrics.recall > 0.90",
)
2 - Searching By Parameters
Parameters capture model configuration. Use the params. prefix and remember that all parameter values are stored as strings:
# Find specific model types
rf_models = mlflow.search_logged_models(
experiment_ids=["1"], filter_string="params.model_type = 'RandomForest'"
)
# Parameter combination search
tuned_rf_models = mlflow.search_logged_models(
experiment_ids=["1"],
filter_string="params.model_type = 'RandomForest' AND params.n_estimators = '200'",
)
3 - Searching By Model Name
Model names are searchable as attributes. Use the name field with supported comparators (=, !=, IN, NOT IN):
# Exact name match
specific_model = mlflow.search_logged_models(
experiment_ids=["1"], filter_string="name = 'SVM_model_5'"
)
# Multiple model names
multiple_models = mlflow.search_logged_models(
experiment_ids=["1"],
filter_string="name IN ('SVM_model_5', 'RandomForest_model_0')",
)
# Exclude specific model
not_svm = mlflow.search_logged_models(
experiment_ids=["1"], filter_string="name != 'SVM_model_4'"
)
4 - Searching By Model Attributes
Attributes include model metadata like creation time. No prefix is needed for attributes:
# Find recently created models (timestamp in milliseconds)
import time
last_week = int((time.time() - 7 * 24 * 60 * 60) * 1000)
recent_models = mlflow.search_logged_models(
experiment_ids=["1"], filter_string=f"creation_time > {last_week}"
)
5 - Dataset-Specific Metric Filtering
One powerful feature of search_logged_models is the ability to filter metrics based on specific datasets:
# Find models with high accuracy on test dataset
test_accurate_models = mlflow.search_logged_models(
experiment_ids=["1"],
filter_string="metrics.accuracy > 0.9",
datasets=[{"dataset_name": "test_dataset", "dataset_digest": "abc123"}], # Optional
)
# Multiple dataset conditions
multi_dataset_models = mlflow.search_logged_models(
experiment_ids=["1"],
filter_string="metrics.accuracy > 0.85",
datasets=[{"dataset_name": "test_dataset"}, {"dataset_name": "validation_dataset"}],
)
6 - Complex Queries
Combine multiple conditions for sophisticated model discovery:
# Production-ready RandomForest models with high performance
production_ready = mlflow.search_logged_models(
experiment_ids=["1"],
filter_string="""
params.model_type = 'RandomForest'
AND metrics.accuracy > 0.9
AND metrics.precision > 0.88
""",
)
Programmatic Search with Python
The Python API provides powerful capabilities for searching logged models programmatically.
Using the Fluent API
mlflow.search_logged_models() provides a convenient interface for model search:
import mlflow
# Basic search with pandas output (default)
models_df = mlflow.search_logged_models(
experiment_ids=["1"], filter_string="metrics.accuracy > 0.9"
)
# Check available columns
print("Available columns:", models_df.columns.tolist())
print("\nModel information:")
print(models_df[["name", "source_run_id"]])
# Get results as a list instead of DataFrame
models_list = mlflow.search_logged_models(
experiment_ids=["1"], filter_string="metrics.accuracy > 0.9", output_format="list"
)
for model in models_list:
print(f"Model: {model.name}, Run ID: {model.source_run_id}")
Using the Client API
mlflow.client.MlflowClient.search_logged_models() offers more control with pagination support:
from mlflow import MlflowClient
client = MlflowClient()
# Search with pagination
page_token = None
all_models = []
while True:
result = client.search_logged_models(
experiment_ids=["1"],
filter_string="metrics.accuracy > 0.85",
max_results=10,
page_token=page_token,
)
all_models.extend(result.to_list())
if not result.token:
break
page_token = result.token
print(f"Found {len(all_models)} models")
Advanced Ordering
Control the order of search results using the order_by parameter:
The order_by functionality for results sorting must be supplied as a list of dictionaries that contains field_name. The ascending key is optional.
# Order by single metric
best_models = mlflow.search_logged_models(
experiment_ids=["1"],
filter_string="params.model_type = 'RandomForest'",
order_by=[
{"field_name": "metrics.accuracy", "ascending": False} # Highest accuracy first
],
)
# Order by dataset-specific metric
dataset_ordered = mlflow.search_logged_models(
experiment_ids=["1"],
filter_string="metrics.f1_score > 0.8",
order_by=[
{
"field_name": "metrics.f1_score",
"ascending": False,
"dataset_name": "test_dataset",
"dataset_digest": "abc123", # Optional
}
],
)
# Multiple ordering criteria
complex_order = mlflow.search_logged_models(
experiment_ids=["1"],
order_by=[
{"field_name": "metrics.accuracy", "ascending": False},
{"field_name": "creation_time", "ascending": True},
],
)
Getting Top N Models
Combine max_results with order_by to get the best models:
# Get top 5 models by accuracy
top_5_models = mlflow.search_logged_models(
experiment_ids=["1"],
max_results=5,
order_by=[{"field_name": "metrics.accuracy", "ascending": False}],
)
# Get the single best model
best_model = mlflow.search_logged_models(
experiment_ids=["1"],
max_results=1,
order_by=[{"field_name": "metrics.f1_score", "ascending": False}],
output_format="list",
)[0]
accuracy_metric = next(
(metric for metric in best_model.metrics if metric.key == "accuracy"), None
)
print(f"Model ID: {best_model.model_id}, Accuracy: {accuracy_metric.value}")
Searching Across Multiple Experiments
Search for models across different experiments:
Do not search over more than 10 experiments when using the search_logged_models API. Excessive search space over
experiments will impact the tracking server's performance.
# Search specific experiments
multi_exp_models = mlflow.search_logged_models(
experiment_ids=["1", "2", "3"], filter_string="metrics.accuracy > 0.9"
)
Common Use Cases
Model Selection for Deployment
Find the best model that meets production criteria:
deployment_candidates = mlflow.search_logged_models(
experiment_ids=exp_ids,
filter_string="""
metrics.accuracy > 0.95
AND metrics.precision > 0.93
""",
datasets=[{"dataset_name": "production_test_set"}],
max_results=1,
order_by=[{"field_name": "metrics.f1_score", "ascending": False}],
)
Model Comparison
Compare different model architectures:
# Get best model of each type
model_types = ["RandomForest", "LogisticRegression", "SVM"]
best_by_type = {}
for model_type in model_types:
models = mlflow.search_logged_models(
experiment_ids=["1"],
filter_string=f"params.model_type = '{model_type}'",
max_results=1,
order_by=[{"field_name": "metrics.accuracy", "ascending": False}],
output_format="list",
)
if models:
best_by_type[model_type] = models[0]
# Compare results
for model_type, model in best_by_type.items():
# Find accuracy in the metrics list
accuracy = None
for metric in model.metrics:
if metric.key == "accuracy":
accuracy = metric.value
break
accuracy_display = f"{accuracy:.4f}" if accuracy is not None else "N/A"
print(
f"{model_type}: Model ID = {model.model_id}, Run ID = {model.source_run_id}, Accuracy = {accuracy_display}"
)
Important Notes
Accessing Metrics from LoggedModel
The LoggedModel objects returned by search_logged_models contain a metrics field with a list of Metric objects:
# Option 1: Access metrics from LoggedModel objects (list output)
models_list = mlflow.search_logged_models(
experiment_ids=["1"], filter_string="metrics.accuracy > 0.9", output_format="list"
)
for model in models_list:
print(f"\nModel: {model.name}")
# Access metrics as a list of Metric objects
for metric in model.metrics:
print(f" {metric.key}: {metric.value}")
# Option 2: Use the DataFrame output which includes flattened metrics
models_df = mlflow.search_logged_models(
experiment_ids=["1"], filter_string="metrics.accuracy > 0.9", output_format="pandas"
)
# The DataFrame has a 'metrics' column containing the list of Metric objects
first_model_metrics = models_df.iloc[0].get("metrics", [])
for metric in first_model_metrics:
print(f"{metric.key}: {metric.value}")
Summary
The search_logged_models API provides a powerful way to discover and compare models in MLflow. By combining flexible filtering, dataset-aware metrics, and ordering capabilities, you can efficiently find the best models for your use case from potentially thousands of candidates.
Key takeaways:
- Use SQL-like syntax with
metrics.,params., andtags.prefixes - Filter metrics by specific datasets for fair comparison
- Combine multiple conditions with AND (OR is not supported)
- Use ordering and max_results to find top performers
- Choose between DataFrame or list output formats based on your needs
Whether you're selecting models for deployment, comparing architectures, or tracking model evolution, mastering the search API will make your MLflow workflow more efficient and powerful.