Models From Code
Models from Code is available in MLflow 2.12.2 and above. For earlier versions, use the legacy serialization methods outlined in the Custom Python Model documentation.
Models from Code is designed for models without optimized weights (GenAI Agents, applications, custom logic). For traditional ML/DL models with trained weights, use the built-in log_model() APIs or custom PythonModel with mlflow.pyfunc.log_model().
Models from Code transforms how you define, store, and load custom models and applications. Instead of relying on complex serialization, it saves your model as readable Python scripts, making development more transparent and debugging significantly easier.
Why Models From Code?
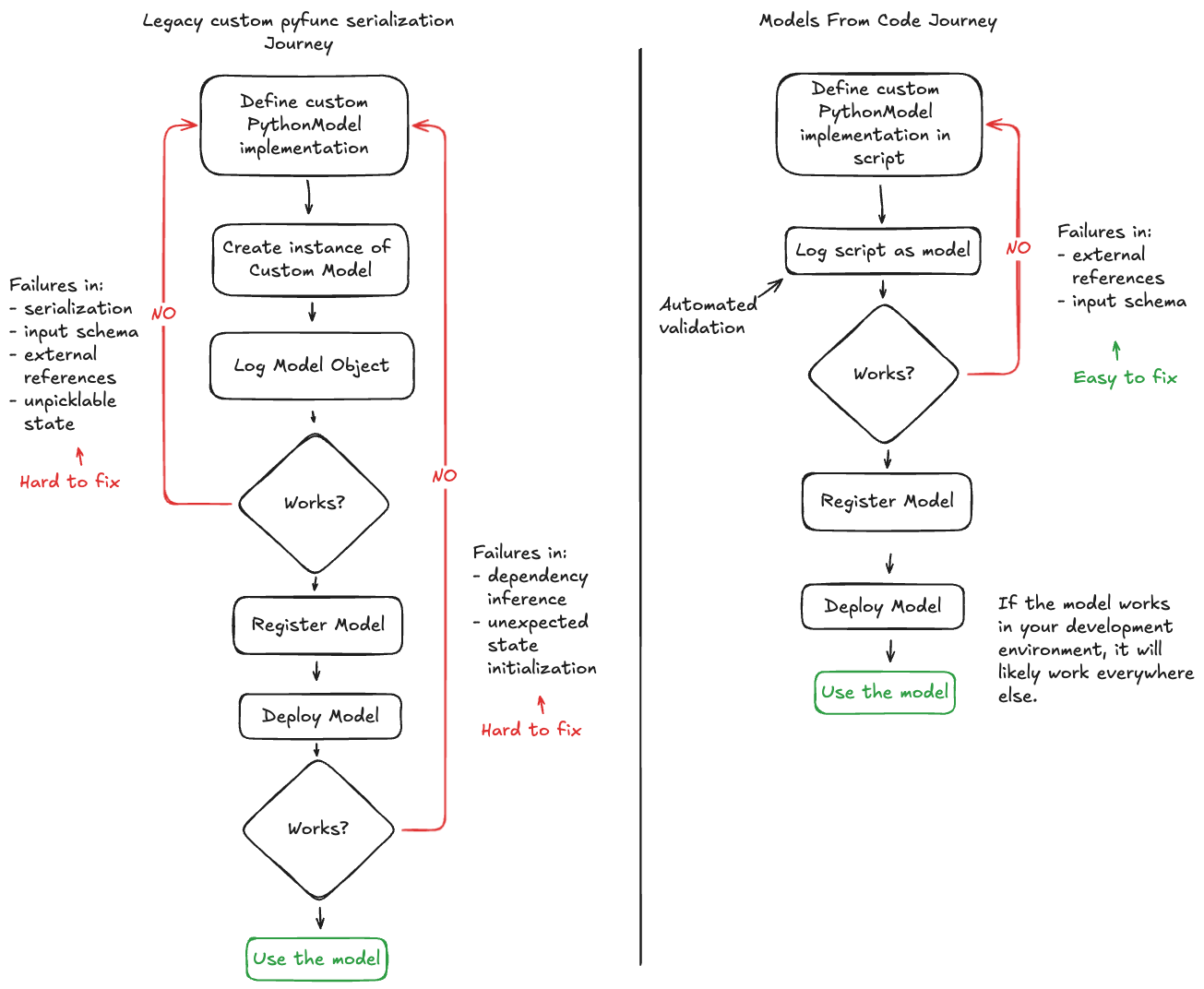
The key difference lies in how models are represented during serialization:
Legacy Approach - Serializes model objects using cloudpickle or custom serializers, creating binary files that can be difficult to debug and have compatibility limitations.
Models From Code - Saves simple Python scripts with your model definition, making them readable, debuggable, and portable across environments.
Key Advantages
Transparency and Readability - Your model code is stored as plain Python scripts, making it easy to understand and debug directly in the MLflow UI.
Reduced Debugging Complexity - No more trial-and-error with serialization issues. What you write is exactly what gets executed.
Better Compatibility - Eliminates pickle/cloudpickle limitations like Python version dependencies, complex object serialization issues, and performance bottlenecks.
Enhanced Security - Human-readable code makes it easier to audit and verify model behavior before deployment.
Core Requirements
Understanding these key concepts will help you use Models from Code effectively:
Script Execution
Your model script is executed during logging to validate correctness. Ensure any external dependencies or authentication are properly configured in your logging environment.
Import Management
Only include imports you actually use. MLflow infers requirements from all top-level imports, so unused imports will unnecessarily bloat your model's dependencies.
External Dependencies
Non-pip installable packages must be specified via code_paths. The system doesn't automatically capture external references beyond standard package imports.
Use a linter to identify unused imports while developing. This keeps your model's requirements clean and deployment lightweight.
Model code is stored in plain text. Never include sensitive information like API keys or passwords in your scripts. Use environment variables or secure configuration management instead.
Development in Jupyter Notebooks
Jupyter notebooks are excellent for AI development, but Models from Code requires Python scripts (.py files). Fortunately, IPython's %%writefile magic command bridges this gap perfectly.
Using %%writefile
The %%writefile magic command captures cell contents and writes them to a file:
# %%writefile "./hello.py" # Uncomment to create the file locally
print("hello!")
This creates a hello.py file containing:
print("hello!")
Best Practices for Jupyter
Overwrite, Don't Append - Use the default %%writefile behavior rather than the -a append option to avoid duplicate code and debugging confusion.
Cell-by-Cell Development - Each %%writefile cell creates one script file. This keeps your model definition clean and focused.
Immediate Testing - You can run your generated script immediately after writing it to verify it works correctly.
Examples and Patterns
- Simple Custom Model
- Multi-File Dependencies
- LangChain Integration
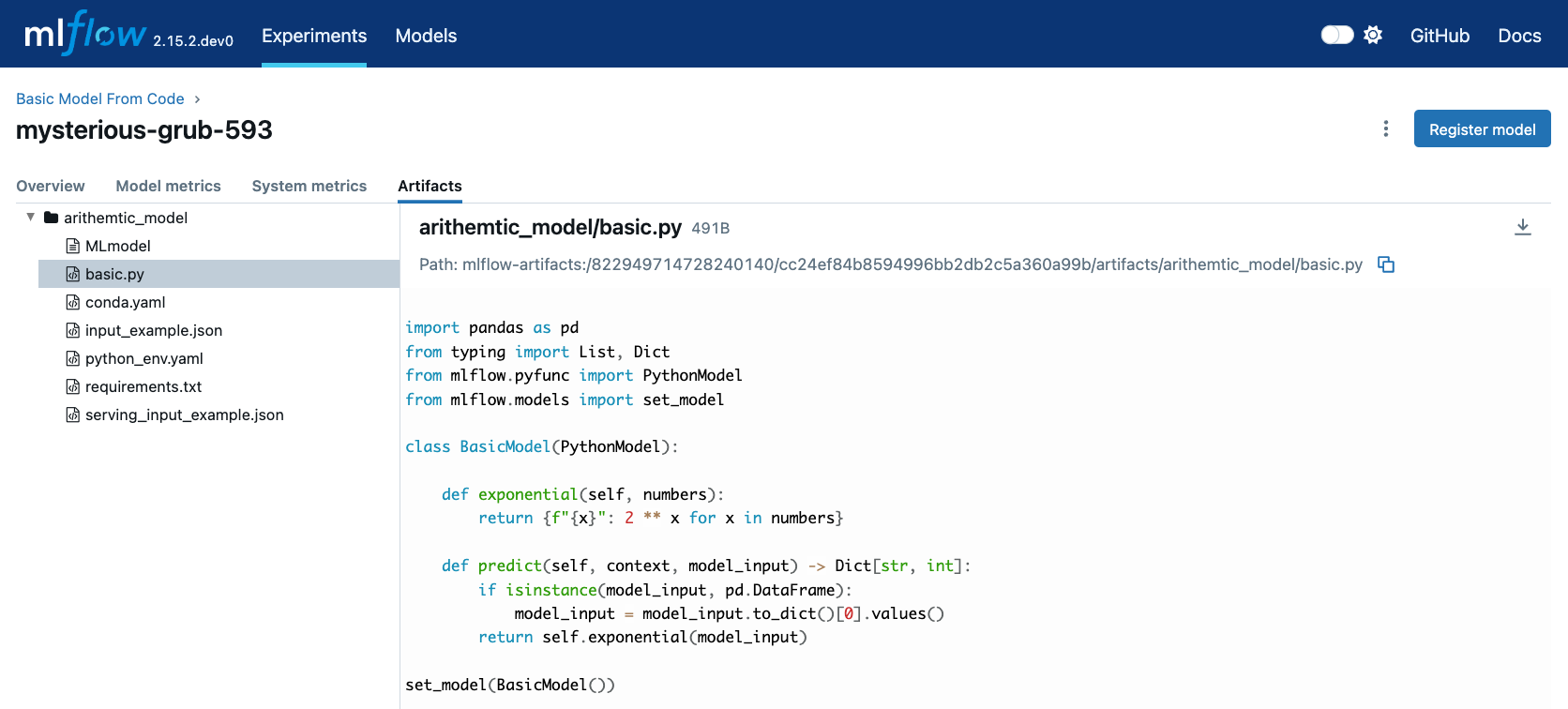
This example demonstrates the basics of Models from Code with a simple mathematical model.
Creating the Model Script
# If running in a Jupyter notebook, uncomment the next line:
# %%writefile "./basic.py"
import pandas as pd
from typing import List, Dict
from mlflow.pyfunc import PythonModel
from mlflow.models import set_model
class BasicModel(PythonModel):
def exponential(self, numbers):
return {f"{x}": 2**x for x in numbers}
def predict(self, context, model_input) -> Dict[str, float]:
if isinstance(model_input, pd.DataFrame):
model_input = list(model_input.iloc[0].values())
return self.exponential(model_input)
# This tells MLflow which object to use for inference
set_model(BasicModel())
Logging the Model
import mlflow
mlflow.set_experiment("Basic Model From Code")
model_info = mlflow.pyfunc.log_model(
python_model="basic.py", # Path to your script
name="arithmetic_model",
input_example=[42.0, 24.0],
)
Using the Model
# Load and use the model
loaded_model = mlflow.pyfunc.load_model(model_info.model_uri)
# Make predictions
result = loaded_model.predict([2.2, 3.1, 4.7])
print(result) # {'2.2': 4.59, '3.1': 8.57, '4.7': 25.99}
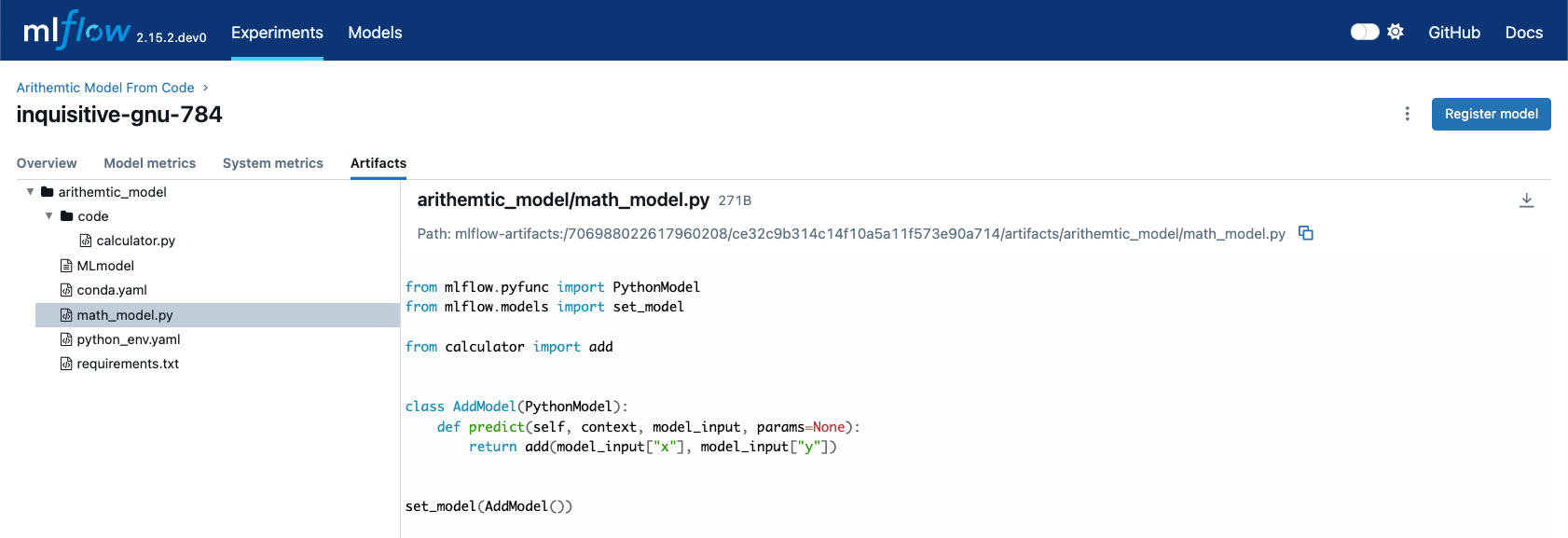
This example shows how to work with multiple Python files using the code_paths feature.
Creating Helper Functions
First, create a utility file with shared functions:
# If running in a Jupyter notebook, uncomment the next line:
# %%writefile "./calculator.py"
def add(x, y):
return x + y
def multiply(x, y):
return x * y
def calculate_compound_interest(principal, rate, time):
return principal * (1 + rate) ** time
Creating the Main Model
Next, create your model that uses the helper functions:
# If running in a Jupyter notebook, uncomment the next line:
# %%writefile "./math_model.py"
from mlflow.pyfunc import PythonModel
from mlflow.models import set_model
from calculator import add, multiply, calculate_compound_interest
class MathModel(PythonModel):
def predict(self, context, model_input, params=None):
operation = model_input.get("operation", "add")
if operation == "add":
return add(model_input["x"], model_input["y"])
elif operation == "multiply":
return multiply(model_input["x"], model_input["y"])
elif operation == "compound_interest":
return calculate_compound_interest(
model_input["principal"], model_input["rate"], model_input["time"]
)
else:
raise ValueError(f"Unknown operation: {operation}")
set_model(MathModel())
Logging with Dependencies
import mlflow
mlflow.set_experiment("Math Model From Code")
with mlflow.start_run():
model_info = mlflow.pyfunc.log_model(
python_model="math_model.py",
name="math_model",
code_paths=["calculator.py"], # Include dependency
input_example={"operation": "add", "x": 5, "y": 3},
)
Testing the Multi-Function Model
loaded_model = mlflow.pyfunc.load_model(model_info.model_uri)
# Test different operations
print(loaded_model.predict({"operation": "add", "x": 10, "y": 5})) # 15
print(loaded_model.predict({"operation": "multiply", "x": 4, "y": 7})) # 28
print(
loaded_model.predict(
{"operation": "compound_interest", "principal": 1000, "rate": 0.05, "time": 10}
)
) # 1628.89
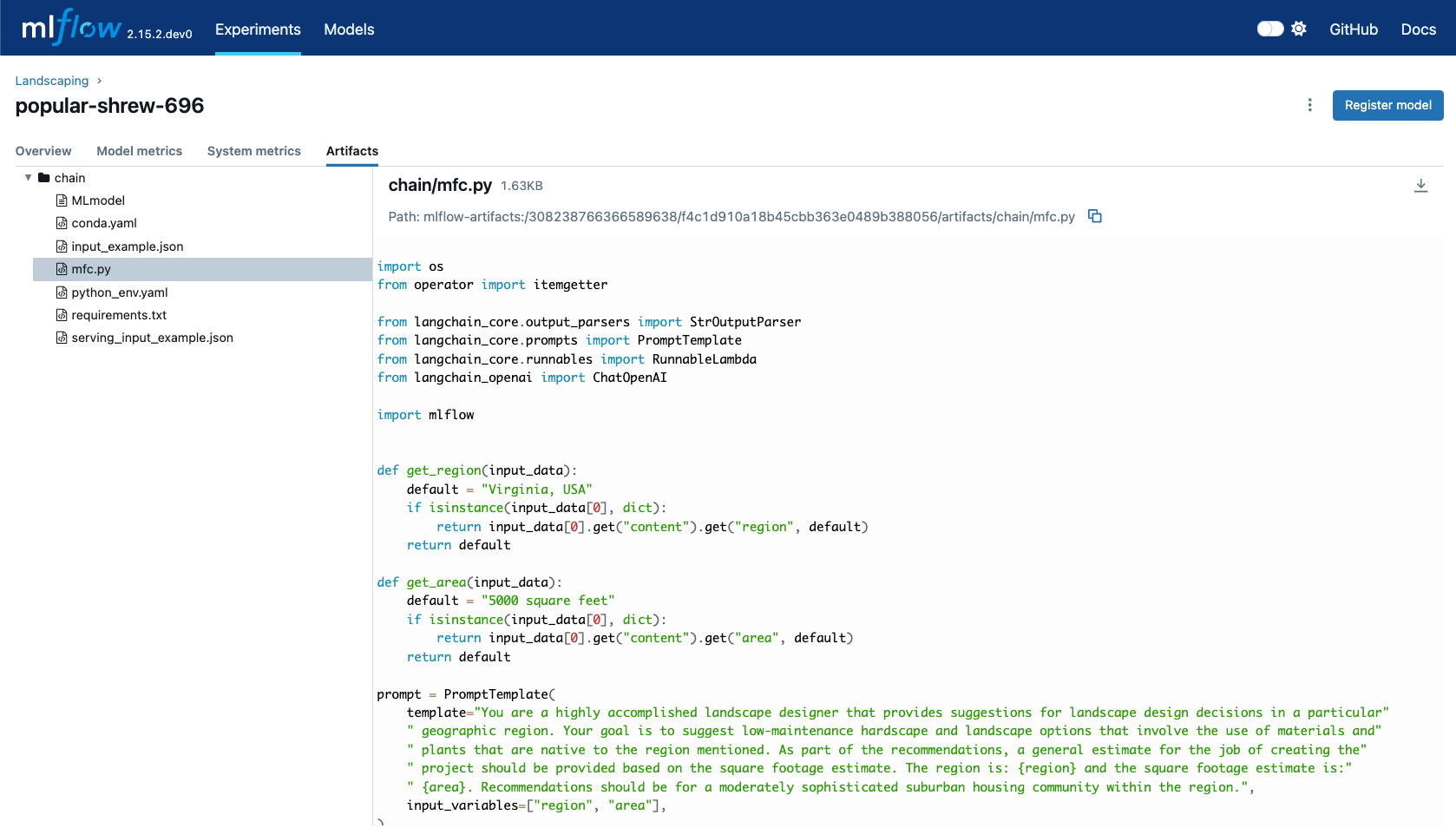
This example demonstrates MLflow's native LangChain Models from Code support for building AI applications.
Creating a LangChain Model
# If running in a Jupyter notebook, uncomment the next line:
# %%writefile "./landscape_advisor.py"
import os
from operator import itemgetter
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda
from langchain_openai import ChatOpenAI
import mlflow
def get_region(input_data):
"""Extract region from input, with fallback default."""
default = "Virginia, USA"
if isinstance(input_data[0], dict):
return input_data[0].get("content", {}).get("region", default)
return default
def get_area(input_data):
"""Extract area from input, with fallback default."""
default = "5000 square feet"
if isinstance(input_data[0], dict):
return input_data[0].get("content", {}).get("area", default)
return default
# Define the prompt template
prompt = PromptTemplate(
template="""You are a highly accomplished landscape designer providing suggestions
for landscape design decisions in a particular geographic region.
Your goal is to suggest low-maintenance hardscape and landscape options using
materials and plants native to the specified region. Include a general cost
estimate based on the square footage provided.
Region: {region}
Square Footage: {area}
Provide recommendations for a moderately sophisticated suburban housing community.""",
input_variables=["region", "area"],
)
# Initialize the language model
model = ChatOpenAI(model="gpt-4o", temperature=0.95, max_tokens=4096)
# Create the chain using LangChain Expression Language (LCEL)
chain = (
{
"region": itemgetter("messages") | RunnableLambda(get_region),
"area": itemgetter("messages") | RunnableLambda(get_area),
}
| prompt
| model
| StrOutputParser()
)
# Set this chain as the model
mlflow.models.set_model(chain)
Logging the LangChain Model
import mlflow
mlflow.set_experiment("Landscape Design Advisor")
input_example = {
"messages": [
{
"role": "user",
"content": {
"region": "Austin, TX, USA",
"area": "1750 square feet",
},
}
]
}
with mlflow.start_run():
model_info = mlflow.langchain.log_model(
lc_model="landscape_advisor.py", # Path to your script
name="landscape_chain",
input_example=input_example,
)
Using the LangChain Model
# Load the model
landscape_advisor = mlflow.langchain.load_model(model_info.model_uri)
# Create a query
query = {
"messages": [
{
"role": "user",
"content": {
"region": "Raleigh, North Carolina USA",
"area": "3850 square feet",
},
},
]
}
# Get landscape recommendations
response = landscape_advisor.invoke(query)
print(response)
Troubleshooting Common Issues
- Dependency Management
- Security & Logging
- Performance Optimization
NameError When Loading Models
Problem: Getting NameError when loading your saved model.
Solution: Ensure all required imports are defined within your model script:
# ❌ Bad - imports missing in script
def predict(self, context, model_input):
return pd.DataFrame(model_input) # NameError: pd not defined
# ✅ Good - imports included
import pandas as pd
def predict(self, context, model_input):
return pd.DataFrame(model_input)
ImportError with External Dependencies
Problem: ImportError when loading models with external dependencies.
Solution: Use code_paths for non-PyPI dependencies:
mlflow.pyfunc.log_model(
python_model="my_model.py",
name="model",
code_paths=["utils.py", "helpers/"], # Include external files
extra_pip_requirements=["custom-package==1.0.0"], # Manual requirements
)
Bloated Requirements File
Problem: requirements.txt contains unnecessary packages.
Solution: Clean up your imports to only include what you use:
# ❌ Bad - unused imports
import pandas as pd
import numpy as np
import tensorflow as tf
import torch
from sklearn.ensemble import RandomForestClassifier
def predict(self, context, model_input):
return {"result": model_input * 2} # Only uses basic operations
# ✅ Good - minimal imports
def predict(self, context, model_input):
return {"result": model_input * 2}
Accidentally Included Sensitive Data
Problem: API keys or secrets were included in your model script.
Immediate Actions:
- Delete the MLflow run: Use the UI or
delete_run()API - Clean up artifacts: Run
mlflow gcCLI command - Rotate compromised credentials
- Re-log the model with proper security practices
Prevention:
# ❌ Bad - hardcoded secrets
api_key = "sk-abc123..."
model = ChatOpenAI(api_key=api_key)
# ✅ Good - environment variables
import os
model = ChatOpenAI(api_key=os.getenv("OPENAI_API_KEY"))
Model Execution During Logging
Problem: Your model makes external calls during logging.
Explanation: MLflow validates your code by executing it. Ensure your logging environment has proper authentication configured.
Best Practice:
# Handle authentication gracefully
try:
# External service calls during initialization
client = ExternalService(api_key=os.getenv("API_KEY"))
client.validate_connection()
except Exception as e:
print(f"Warning: Could not validate external service: {e}")
# Continue with model definition
Optimizing Model Loading
Lazy Loading: Initialize expensive resources only when needed:
class OptimizedModel(PythonModel):
def __init__(self):
self._expensive_resource = None
@property
def expensive_resource(self):
if self._expensive_resource is None:
self._expensive_resource = load_expensive_model()
return self._expensive_resource
def predict(self, context, model_input):
return self.expensive_resource.predict(model_input)
Minimizing Dependencies
Conditional Imports: Only import what you need for specific operations:
def predict(self, context, model_input):
operation = model_input.get("type", "simple")
if operation == "complex":
import tensorflow as tf # Only import when needed
return self._tensorflow_predict(model_input)
else:
return self._simple_predict(model_input)
Memory Management
Resource Cleanup: Properly manage resources in your model:
class ResourceManagedModel(PythonModel):
def __enter__(self):
self.connection = create_connection()
return self
def __exit__(self, exc_type, exc_val, exc_tb):
if hasattr(self, "connection"):
self.connection.close()
def predict(self, context, model_input):
# Use self.connection for predictions
pass
Migration from Legacy Serialization
If you're currently using legacy model serialization, here's how to migrate:
Before (Legacy)
class MyModel(mlflow.pyfunc.PythonModel):
def predict(self, context, model_input):
return model_input * 2
# Log object instance
model_instance = MyModel()
mlflow.pyfunc.log_model(python_model=model_instance, name="model")
After (Models from Code)
# Save as script: my_model.py
# %%writefile "./my_model.py"
import mlflow
from mlflow.pyfunc import PythonModel
from mlflow.models import set_model
class MyModel(PythonModel):
def predict(self, context, model_input):
return model_input * 2
set_model(MyModel())
# Log script path
mlflow.pyfunc.log_model(python_model="my_model.py", name="model")
Best Practices Summary
Code Organization
- Keep model scripts focused and minimal
- Use descriptive names for model files and functions
- Organize related functionality into separate modules using
code_paths
Security
- Never hardcode sensitive information in model scripts
- Use environment variables for configuration
- Review code before logging to ensure no secrets are included
Performance
- Import only what you need to minimize dependencies
- Use lazy loading for expensive resources
- Consider memory management for long-running models
Development Workflow
- Use
%%writefilein Jupyter for rapid prototyping - Test your scripts independently before logging
- Use linters to catch unused imports and other issues
Additional Resources
For more information on related topics: