Model Signatures and Input Examples
Model signatures and input examples are foundational components that define how your models should be used, ensuring consistent and reliable interactions across MLflow's ecosystem.
What Are Model Signatures and Input Examples?
Model Signature - Defines the expected format for model inputs, outputs, and parameters. Think of it as a contract that specifies exactly what data your model expects and what it will return.
Model Input Example - Provides a concrete example of valid model input. This helps developers understand the required data format and validates that your model works correctly.

Why They Matter
Model signatures and input examples provide crucial benefits:
- Consistency: Ensure all model interactions follow the same data format
- Validation: Catch data format errors before they reach your model
- Documentation: Serve as living documentation for model usage
- Deployment Safety: Enable MLflow deployment tools to validate requests automatically
- UI Integration: Allow MLflow UI to display clear model requirements
Model signatures are REQUIRED for registering models in Databricks Unity Catalog. Unity Catalog enforces concrete type definitions for all registered models and will reject models without proper signatures. Always include a signature when logging models that you plan to register in Databricks environments.
# ✅ Required for Databricks registration
mlflow.sklearn.log_model(
model,
name="my_model",
input_example=X_sample, # Generates required signature
signature=signature, # Or provide explicit signature
)
# ❌ Will fail in Databricks Unity Catalog
mlflow.sklearn.log_model(model, name="my_model") # No signature
Quick Start: Adding Signatures to Your Models
The easiest way to add a signature is to provide an input example when logging your model:
import mlflow
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
# Load data and train model
iris = load_iris(as_frame=True)
X = iris.data
y = iris.target
model = RandomForestClassifier().fit(X, y)
with mlflow.start_run():
# The input example automatically generates a signature
mlflow.sklearn.log_model(
model, name="iris_model", input_example=X.iloc[[0]] # First row as example
)
MLflow automatically:
- Infers the signature from your input example
- Validates the model works with the example
- Stores both signature and example with your model
MLflow automatically generates model signatures when you provide an input_example during model logging. This works for all model flavors and is the recommended approach for most use cases.
Understanding Model Signatures
Model signatures consist of three components:
- Inputs Schema
- Outputs Schema
- Parameters Schema
Defines the structure and types of data your model expects:
# Column-based signature (DataFrames)
input_schema = Schema(
[
ColSpec("double", "sepal_length"),
ColSpec("double", "sepal_width"),
ColSpec("string", "species", required=False), # Optional field
]
)
# Tensor-based signature (NumPy arrays)
input_schema = Schema(
[TensorSpec(np.dtype(np.float32), (-1, 28, 28, 1))] # Batch of 28x28 images
)
Key Features:
Support for both tabular (DataFrame) and tensor (NumPy) data, optional fields using required=False, and rich data type support including arrays and objects.
Specifies what your model returns:
# Single prediction column
output_schema = Schema([ColSpec("long", "prediction")])
# Multiple outputs
output_schema = Schema(
[
ColSpec("double", "probability"),
ColSpec("string", "predicted_class"),
ColSpec("long", "confidence_score"),
]
)
# Tensor output
output_schema = Schema(
[TensorSpec(np.dtype(np.float32), (-1, 10))] # 10-class probabilities
)
Defines optional inference parameters (like temperature, max_length):
# Define inference parameters
params_schema = ParamSchema(
[
ParamSpec("temperature", "double", 0.7), # Default temperature
ParamSpec("max_tokens", "long", 100), # Default max tokens
ParamSpec("stop_words", "string", [".", "!"], (-1,)), # List parameter
]
)
# Use in model signature
signature = ModelSignature(
inputs=input_schema, outputs=output_schema, params=params_schema
)
Common Parameters:
temperature controls randomness in generation, max_length/max_tokens limits output length, top_k and top_p control sampling strategies, and repetition_penalty reduces repetitive outputs.
Signature Types Overview
MLflow supports two primary signature types:
Column-Based Signatures - For tabular data (DataFrames, dictionaries):
# Perfect for traditional ML models
{"feature_1": 1.5, "feature_2": "category_a", "feature_3": [1, 2, 3]}
Tensor-Based Signatures - For array data (images, audio, embeddings):
# Perfect for deep learning models
np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [1, 2, 3]]]) # Shape: (2, 2, 3)
Type Hints for Model Signatures
Type hint support was introduced in MLflow 2.20.0. If you are using an earlier version of MLflow, see the Working with Signatures section.
You can use Python type hints to automatically define model signatures and enable data validation. This provides a more Pythonic way to specify your model's interface while getting automatic validation and schema inference.
- Overview & Benefits
- Supported Type Hints
- Pydantic Models
- Validation & Conversion
- Special Type Hints
- Serving & Deployment
Quick Start with Type Hints
import mlflow
from typing import List, Dict, Optional
import pydantic
class Message(pydantic.BaseModel):
role: str
content: str
metadata: Optional[Dict[str, str]] = None
class CustomModel(mlflow.pyfunc.PythonModel):
def predict(self, model_input: List[Message]) -> List[str]:
# Signature automatically inferred from type hints!
return [msg.content for msg in model_input]
# Log model - signature is auto-generated from type hints
with mlflow.start_run():
mlflow.pyfunc.log_model(
name="chat_model",
python_model=CustomModel(),
input_example=[
{"role": "user", "content": "Hello"}
], # Validates against type hints
)
Key Benefits
- Automatic Validation: Input data validated against type hints at runtime
- Schema Inference: Model signature automatically generated from type annotations
- Type Safety: Catch type mismatches before they reach your model
- IDE Support: Better autocomplete and error detection during development
- Documentation: Type hints serve as self-documenting code
- Consistency: Same validation for PythonModel instances and loaded PyFunc models
When to Use Type Hints
✅ Recommended for: Complex data structures (chat messages, tool definitions, nested objects), models requiring strict input validation, teams using modern Python development practices, and GenAI and LLM applications with structured inputs.
⚠️ Consider alternatives for: Simple tabular data (DataFrames work fine with input examples), legacy codebases without type hint adoption, and models with highly dynamic input structures.
Input Type Requirements
Input signatures must be List[...] since PythonModel expects batch data:
# ✅ Correct - Always use List wrapper
def predict(self, model_input: List[str]) -> List[str]:
...
def predict(self, model_input: List[Message]) -> List[Dict]:
...
# ❌ Incorrect - Missing List wrapper
def predict(self, model_input: str) -> str:
...
def predict(self, model_input: Message) -> Dict:
...
Primitive Types
List[str] # String inputs
List[int] # Integer inputs
List[float] # Float inputs
List[bool] # Boolean inputs
List[bytes] # Binary data
List[datetime.datetime] # Timestamps
Collection Types
List[List[str]] # Nested lists
List[Dict[str, int]] # Dictionaries
List[Dict[str, List[str]]] # Complex nested structures
Union and Optional Types
List[Union[int, str]] # Multiple possible types (becomes AnyType)
List[Optional[str]] # Optional fields (in Pydantic models only)
List[Any] # Any type (no validation)
Pydantic Models (Recommended)
class UserData(pydantic.BaseModel):
name: str
age: int
email: Optional[str] = None # Optional with default
preferences: List[str] = [] # List with default
List[UserData] # Clean, validated structure
Type Hint to Schema Mapping
| Type Hint | Generated Schema |
|---|---|
List[str] | Schema([ColSpec(type=DataType.string)]) |
List[List[str]] | Schema([ColSpec(type=Array(DataType.string))]) |
List[Dict[str, str]] | Schema([ColSpec(type=Map(DataType.string))]) |
List[Union[int, str]] | Schema([ColSpec(type=AnyType())]) |
List[Message] | Schema([ColSpec(type=Object(...))]) |
Basic Pydantic Usage
import pydantic
from typing import Optional, List, Dict
class Message(pydantic.BaseModel):
role: str
content: str
timestamp: Optional[str] = None
class CustomModel(mlflow.pyfunc.PythonModel):
def predict(self, model_input: List[Message]) -> List[str]:
return [f"{msg.role}: {msg.content}" for msg in model_input]
# Both work - automatic conversion
model.predict([Message(role="user", content="Hi")]) # Pydantic object
model.predict([{"role": "user", "content": "Hi"}]) # Dict (auto-converted)
Complex Nested Models
class FunctionParams(pydantic.BaseModel):
properties: Dict[str, str]
type: str = "object"
required: Optional[List[str]] = None
class ToolDefinition(pydantic.BaseModel):
name: str
description: Optional[str] = None
parameters: Optional[FunctionParams] = None
class ChatRequest(pydantic.BaseModel):
messages: List[Message]
tools: Optional[List[ToolDefinition]] = None
temperature: float = 0.7
@mlflow.pyfunc.utils.pyfunc
def advanced_predict(model_input: List[ChatRequest]) -> List[Dict[str, str]]:
results = []
for request in model_input:
# Type validation ensures request.messages exists and is properly typed
response = {"response": f"Processed {len(request.messages)} messages"}
if request.tools:
response["tools_count"] = str(len(request.tools))
results.append(response)
return results
Flexible Base Classes
class BaseMessage(pydantic.BaseModel):
model_config = pydantic.ConfigDict(extra="allow") # Allow extra fields
role: str
content: str
class SystemMessage(BaseMessage):
system_prompt: str
class UserMessage(BaseMessage):
user_id: str
@mlflow.pyfunc.utils.pyfunc
def flexible_predict(model_input: List[BaseMessage]) -> List[str]:
# Input automatically converted to BaseMessage objects
# Extra fields from subclasses preserved
results = []
for msg in model_input:
result = f"{msg.role}: {msg.content}"
if hasattr(msg, "system_prompt"):
result += f" (system: {msg.system_prompt})"
elif hasattr(msg, "user_id"):
result += f" (user: {msg.user_id})"
results.append(result)
return results
Pydantic Best Practices
Always provide defaults for optional fields:
# ✅ Good - Optional fields have defaults
class Message(pydantic.BaseModel):
role: str
content: str
metadata: Optional[Dict[str, str]] = None
timestamp: Optional[str] = None
# ❌ Bad - Optional field without default
class Message(pydantic.BaseModel):
role: str
content: str
metadata: Optional[Dict[str, str]] # Will cause validation errors
Automatic Data Validation
Type hints enable automatic validation for both PythonModel instances and loaded PyFunc models:
model = CustomModel()
# ✅ Works: Pydantic objects
input_data = [Message(role="user", content="Hello")]
result = model.predict(input_data)
# ✅ Works: Dictionaries (auto-converted to Pydantic objects)
input_data = [{"role": "user", "content": "Hello"}]
result = model.predict(input_data)
# ❌ Fails: Missing required fields
input_data = [{"role": "user"}] # Missing 'content'
model.predict(input_data) # Raises validation error
# ❌ Fails: Wrong data type
input_data = ["hello"] # Expected dict/Pydantic object
model.predict(input_data) # Raises validation error
Data Conversion Examples
# Input: Dictionary
input_dict = {"role": "system", "content": "Hello", "metadata": {"source": "api"}}
# Automatically converted to: Message object
# Message(role="system", content="Hello", metadata={"source": "api"})
# Works for nested structures too
complex_input = {
"messages": [{"role": "user", "content": "Hi"}],
"tools": [{"name": "search", "description": "Web search"}],
"temperature": 0.5,
}
# Automatically converted to: ChatRequest object with nested Message and ToolDefinition objects
Validation Error Examples
# Missing required field
try:
model.predict([{"role": "system"}]) # Missing 'content'
except Exception as e:
print(e)
# Output: 1 validation error for Message
# content
# Field required [type=missing, input_value={'role': 'system'}, input_type=dict]
# Wrong data type
try:
model.predict(["hello"]) # Expected dict/object
except Exception as e:
print(e)
# Output: Failed to validate data against type hint `list[Message]`, invalid elements:
# [('hello', "Expecting example to be a dictionary or pydantic model instance...")]
Validation Scope
MLflow validates input data against type hints but does not validate model output. The output type hint is used only for model signature inference.
TypeFromExample
For cases where you want automatic type inference from your input example:
from mlflow.types.type_hints import TypeFromExample
class FlexibleModel(mlflow.pyfunc.PythonModel):
def predict(self, model_input: TypeFromExample):
# Type determined by input_example at logging time
return [
item.upper() if isinstance(item, str) else str(item) for item in model_input
]
# Input example determines the expected type
with mlflow.start_run():
mlflow.pyfunc.log_model(
name="flexible_model",
python_model=FlexibleModel(),
input_example=["sample", "data"], # Expects List[str]
)
# At inference, validates against List[str] type
loaded_model = mlflow.pyfunc.load_model(model_uri)
result = loaded_model.predict(["hello", "world"]) # ✅ Works
Legacy Type Hints (No Validation)
These type hints work but don't provide validation or schema inference:
# Supported but no validation
def predict(self, model_input: pd.DataFrame) -> pd.DataFrame:
...
def predict(self, model_input: np.ndarray) -> np.ndarray:
...
def predict(self, model_input: scipy.sparse.csr_matrix):
...
# You must provide explicit signature or input_example
with mlflow.start_run():
mlflow.pyfunc.log_model(
name="legacy_model",
python_model=model,
input_example=sample_dataframe, # Required for legacy types
)
Using @pyfunc Decorator
For callable functions (not classes):
from mlflow.pyfunc.utils import pyfunc
@pyfunc
def predict(model_input: List[Message]) -> List[str]:
return [msg.content for msg in model_input]
# Same validation works as with PythonModel
predict([{"role": "user", "content": "Hi"}]) # ✅ Auto-converts dict to Message
predict(["hello"]) # ❌ Validation error
Union Types Behavior
# Union types become AnyType (no validation)
def predict(self, model_input: List[Union[str, int]]) -> List[str]:
# MLflow infers this as List[AnyType] - no validation performed
return [str(item) for item in model_input]
# Better approach: Use Pydantic discriminated unions for validation
from typing import Literal
class TextInput(pydantic.BaseModel):
type: Literal["text"] = "text"
content: str
class NumberInput(pydantic.BaseModel):
type: Literal["number"] = "number"
value: int
# Discriminated union with validation
def predict(self, model_input: List[Union[TextInput, NumberInput]]) -> List[str]:
...
Serving Models with Type Hints
When serving models with type hints, always use the inputs key in your JSON request:
# Start local server
mlflow models serve -m runs/<run_id>/model --env-manager local
# Correct request format
curl -X POST http://127.0.0.1:5000/invocations \
-H 'Content-Type: application/json' \
-d '{"inputs": [{"role": "user", "content": "Hello"}]}'
# ❌ Incorrect - missing inputs wrapper
curl -X POST http://127.0.0.1:5000/invocations \
-H 'Content-Type: application/json' \
-d '[{"role": "user", "content": "Hello"}]'
Deployment Best Practices
Input Example Validation:
# Always provide input examples that match your type hints
with mlflow.start_run():
model_info = mlflow.pyfunc.log_model(
name="chat_model",
python_model=CustomModel(),
input_example=[{"role": "user", "content": "test"}], # Matches List[Message]
)
# MLflow validates the input_example against type hints at logging time
Testing Before Deployment:
# Test locally first
model = CustomModel()
test_input = [{"role": "user", "content": "test"}]
# Verify validation works
try:
result = model.predict(test_input)
print("✅ Validation passed")
except Exception as e:
print(f"❌ Validation failed: {e}")
# Test loaded model
loaded_model = mlflow.pyfunc.load_model(model_info.model_uri)
result = loaded_model.predict(test_input)
Production Considerations
Error Handling:
class RobustModel(mlflow.pyfunc.PythonModel):
def predict(self, model_input: List[Message]) -> List[str]:
try:
return [msg.content for msg in model_input]
except Exception as e:
# Log validation errors for monitoring
logger.error(f"Prediction failed: {e}")
raise
Performance: Type validation adds minimal overhead, Pydantic validation is highly optimized, and you should consider caching for repeated validation of similar structures.
Type Hints Best Practices
Development Workflow:
# ✅ Recommended pattern
class MyModel(mlflow.pyfunc.PythonModel):
def predict(self, model_input: List[MyPydanticModel]) -> List[str]:
# Clear type annotations
# Automatic validation
# Good IDE support
return [process(item) for item in model_input]
Key Guidelines:
- Use Pydantic models for complex data structures
- Set default values for optional fields in Pydantic models
- Don't pass explicit
signatureparameter when using type hints - Always provide input examples that match your type hints
- Use
TypeFromExamplewhen you want flexibility without explicit typing - Test validation locally before deployment
- Never pass explicit
signatureparameter when using type hints - MLflow will use the inferred signature and warn if they don't match - Union types become AnyType - use Pydantic discriminated unions for proper validation
- Input examples are required for
TypeFromExampleand legacy type hints
Data Types and Examples
- Column-Based Data Types
- Tensor-Based Data Types
- Inference Parameters
Primitive Types
Python to MLflow type mappings:
Usage of these types support only scalar definitions or 1-dimensional Arrays. Mixed types are not permitted.
| Python Type | MLflow Type | Example | Notes |
|---|---|---|---|
str | string | "hello world" | |
int | long | 42 | 64-bit integers |
np.int32 | integer | np.int32(42) | 32-bit integers |
float | double | 3.14159 | 64-bit floats |
np.float32 | float | np.float32(3.14) | 32-bit floats |
bool | boolean | True | |
np.bool_ | boolean | np.bool_(True) | NumPy boolean |
datetime | datetime | pd.Timestamp("2023-01-01") | |
bytes | binary | b"binary data" | |
bytearray | binary | bytearray(b"data") | |
np.bytes_ | binary | np.bytes_(b"data") | NumPy bytes |
Composite Types
Arrays (Lists/NumPy arrays):
{
"simple_list": ["a", "b", "c"],
"nested_array": [[1, 2], [3, 4], [5, 6]],
"numpy_array": np.array([1.1, 2.2, 3.3]),
}
Objects (Dictionaries):
{"user_profile": {"name": "Alice", "age": 30, "preferences": ["sports", "music"]}}
Optional Fields:
# Include None values to make fields optional
pd.DataFrame(
{
"required_field": [1, 2, 3],
"optional_field": [1.0, None, 3.0], # This becomes optional
}
)
Compatibility Notes
Version Requirements:
- Array and Object types: Require MLflow ≥ 2.10.0
- Spark ML vectors: Require MLflow ≥ 2.15.0
- AnyType: Requires MLflow ≥ 2.19.0
NumPy Data Types
Tensor signatures support all NumPy data types:
np.float32 # 32-bit float
np.float64 # 64-bit float (double)
np.int8 # 8-bit integer
np.int32 # 32-bit integer
np.uint8 # Unsigned 8-bit (common for images)
np.bool_ # Boolean
Shape Specifications
Use -1 for dimensions that can vary (typically batch size):
# Image batch: variable batch size, 28x28 pixels, 1 channel
TensorSpec(np.dtype(np.uint8), (-1, 28, 28, 1))
# Text embeddings: variable batch size, 768-dimensional vectors
TensorSpec(np.dtype(np.float32), (-1, 768))
# Fixed shape: exactly 10 classes
TensorSpec(np.dtype(np.float32), (10,))
Common Patterns
Computer Vision:
# Grayscale images
TensorSpec(np.dtype(np.uint8), (-1, 28, 28, 1))
# RGB images
TensorSpec(np.dtype(np.uint8), (-1, 224, 224, 3))
# Feature maps
TensorSpec(np.dtype(np.float32), (-1, 512, 7, 7))
Natural Language Processing:
# Token IDs
TensorSpec(np.dtype(np.int64), (-1, 512))
# Embeddings
TensorSpec(np.dtype(np.float32), (-1, 768))
# Attention masks
TensorSpec(np.dtype(np.bool_), (-1, 512))
Parameter Specifications
Parameters allow runtime customization of model behavior:
ParamSpec(
name="temperature", # Parameter name
dtype="double", # Data type
default=0.7, # Default value
shape=None, # Shape (None for scalars, (-1,) for lists)
)
Supported Parameter Types
Parameters must be scalars or 1D arrays only. Multi-dimensional arrays are not supported for inference parameters.
| MLflow Type | Python Type | Scalar Example | 1D Array Example |
|---|---|---|---|
string | str | "gpt-4" | ["stop1", "stop2"] |
long | int (64-bit) | 100 | [100, 200, 300] |
integer | int (32-bit) | 50 | [10, 20, 30] |
double | float (64-bit) | 0.7 | [0.1, 0.5, 0.9] |
float | float (32-bit) | 0.5 | [0.1, 0.2, 0.3] |
boolean | bool | True | [True, False, True] |
datetime | datetime | datetime.now() | [datetime1, datetime2] |
binary | bytes | b"data" | [b"data1", b"data2"] |
Common Parameter Patterns
Text Generation:
params_schema = ParamSchema(
[
ParamSpec("temperature", "double", 0.7),
ParamSpec("max_tokens", "long", 100),
ParamSpec("top_p", "double", 0.9),
ParamSpec("frequency_penalty", "double", 0.0),
ParamSpec("stop_sequences", "string", [], (-1,)), # List of strings
]
)
Model Selection:
params_schema = ParamSchema(
[
ParamSpec("model_name", "string", "default"),
ParamSpec("use_cache", "boolean", True),
ParamSpec("timeout", "long", 30),
]
)
Using Parameters at Inference
# Model with parameters
loaded_model = mlflow.pyfunc.load_model(model_uri)
# Use default parameters
result = loaded_model.predict(input_data)
# Override specific parameters
result = loaded_model.predict(input_data, params={"temperature": 0.1, "max_tokens": 50})
Signature Enforcement and Validation
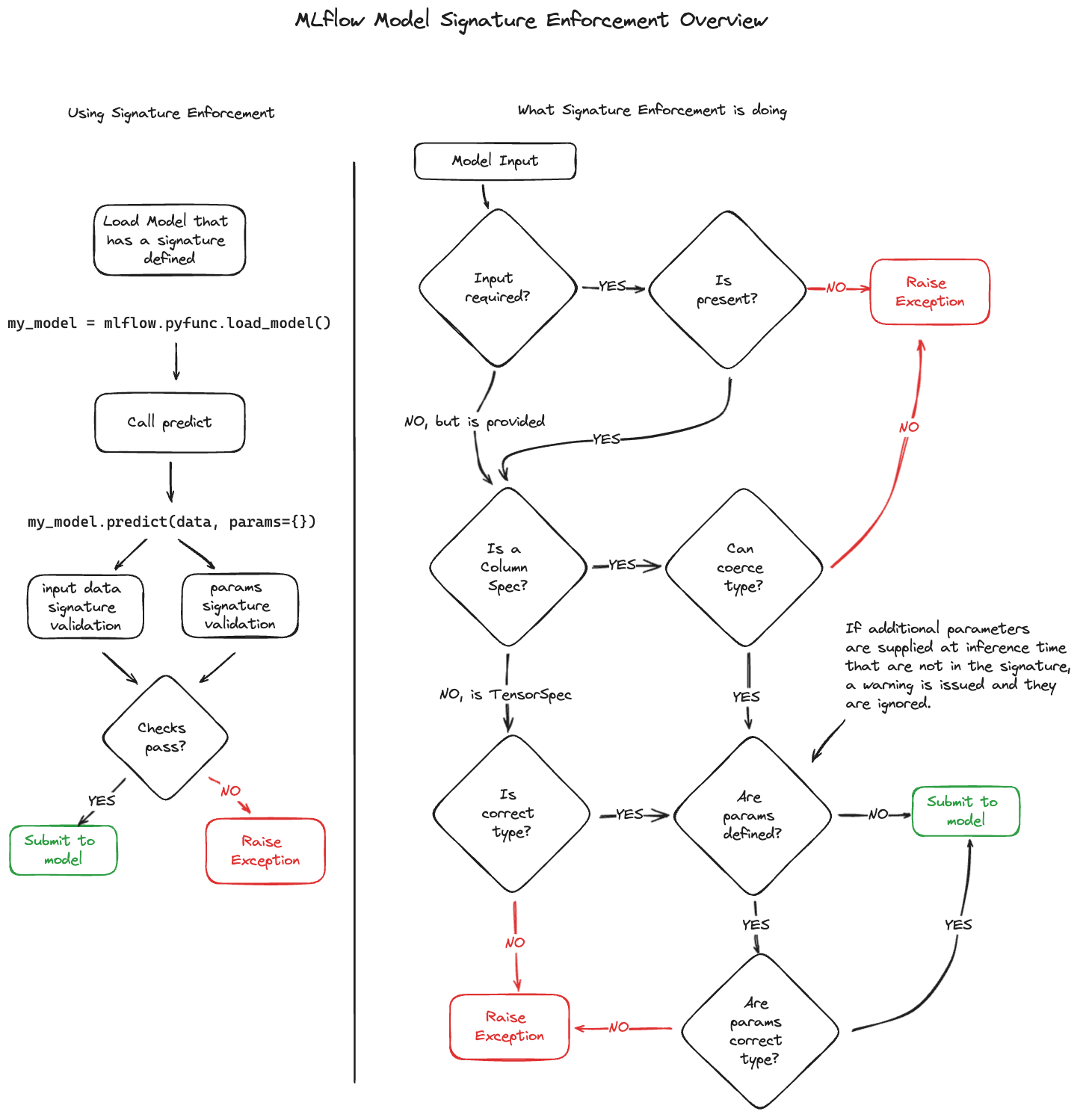
MLflow automatically validates inputs against your model signature when:
- Loading models as PyFunc (
mlflow.pyfunc.load_model) - Using MLflow deployment tools
- Serving models via MLflow's REST API
Validation Rules
Input Validation:
- Required fields: Must be present or validation fails
- Optional fields: Can be missing without errors
- Extra fields: Ignored (not passed to model)
- Type conversion: Safe conversions applied when possible
Parameter Validation:
- Type checking: Parameters must match specified types
- Shape validation: List parameters validated for correct shape
- Default values: Applied when parameters not provided
- Unknown parameters: Generate warnings but don't fail
Handling Common Issues
Integer Columns with Missing Values:
# ❌ Problem: Integer column with NaN becomes float, causing type mismatch
df = pd.DataFrame({"int_col": [1, 2, None]}) # Becomes float64
# ✅ Solution: Define as double from the start
df = pd.DataFrame({"int_col": [1.0, 2.0, None]}) # Stays float64
Type Conversion Examples:
# ✅ Safe conversions (allowed)
int → long # 32-bit to 64-bit integer
int → double # Integer to float
float → double # 32-bit to 64-bit float
# ❌ Unsafe conversions (rejected)
long → double # Potential precision loss
string → int # No automatic parsing
Working with Signatures
- Logging Models with Signatures
- Updating Existing Models
- Advanced Signature Patterns
Automatic Signature Inference
The easiest approach - provide an input example:
import mlflow
from sklearn.ensemble import RandomForestClassifier
# Train your model
model = RandomForestClassifier().fit(X_train, y_train)
with mlflow.start_run():
mlflow.sklearn.log_model(
model,
name="my_model",
input_example=X_train.iloc[[0]], # Signature inferred automatically
)
Manual Signature Creation
For more control, create signatures explicitly:
from mlflow.models import ModelSignature
from mlflow.types.schema import Schema, ColSpec
# Define input schema
input_schema = Schema(
[
ColSpec("double", "feature_1"),
ColSpec("string", "feature_2"),
ColSpec("long", "feature_3", required=False), # Optional
]
)
# Define output schema
output_schema = Schema([ColSpec("double", "prediction")])
# Create signature
signature = ModelSignature(inputs=input_schema, outputs=output_schema)
# Log with explicit signature
with mlflow.start_run():
mlflow.sklearn.log_model(model, name="my_model", signature=signature)
Signature Inference Helper
Use infer_signature for custom workflows:
from mlflow.models import infer_signature
# Generate predictions for signature inference
predictions = model.predict(X_test)
# Infer signature from data
signature = infer_signature(X_test, predictions)
# Log with inferred signature
with mlflow.start_run():
mlflow.sklearn.log_model(model, name="my_model", signature=signature)
Adding Signatures to Logged Models
Use set_signature to add or update signatures on existing models:
from mlflow.models import set_signature, infer_signature
# Load existing model (without signature)
model_uri = "models:/<model_id>"
model = mlflow.pyfunc.load_model(model_uri)
# Create signature from test data
signature = infer_signature(X_test, model.predict(X_test))
# Apply signature to existing model
set_signature(model_uri, signature)
# Verify signature was set
from mlflow.models.model import get_model_info
assert get_model_info(model_uri).signature == signature
Working with Model Registry
For registered models, update the source and create a new version:
from mlflow.client import MlflowClient
client = MlflowClient()
model_name = "my_registered_model"
model_version = 1
# Get existing model version
mv = client.get_model_version(name=model_name, version=model_version)
# Update signature on source artifacts
signature = infer_signature(X_test, predictions)
set_signature(mv.source, signature)
# Create new model version with updated signature
client.create_model_version(name=model_name, source=mv.source, run_id=mv.run_id)
GenAI Model Signatures
For LangChain, OpenAI, and similar models, signatures are automatically inferred when you provide an input example:
# Input example for chat model
input_example = {"messages": [{"role": "user", "content": "What is machine learning?"}]}
# Optional fields example
input_example = [
{"name": "Alice", "message": "Hello"}, # name is present
{"message": "Hi there"}, # name is missing (becomes optional)
]
# Log model - signature auto-generated from input_example
with mlflow.start_run():
mlflow.langchain.log_model(
chain,
name="chat_model",
input_example=input_example, # Signature automatically inferred!
)
Models with Parameters
Include inference parameters in your signature - signatures are automatically inferred when both input and parameters are provided:
# Input data and parameters
input_data = "Translate to French: Hello world"
params = {"temperature": 0.3, "max_tokens": 50, "stop_sequences": [".", "!"]}
# Create signature with parameters - automatically inferred
signature = infer_signature(
input_data, model.predict(input_data), params # Include parameters in signature
)
with mlflow.start_run():
mlflow.transformers.log_model(model, name="translation_model", signature=signature)
Complex Data Structures
Handle nested objects and arrays - signatures automatically inferred from complex input examples:
# Complex input structure
input_example = {
"user_data": {
"id": 12345,
"preferences": ["action", "comedy"],
"metadata": {"created_date": "2023-01-01", "is_premium": True},
},
"context": {"device": "mobile", "location": None}, # Optional field
}
# Signature automatically handles nested structure when provided as input_example
with mlflow.start_run():
mlflow.pyfunc.log_model(
python_model=custom_model,
name="complex_model",
input_example=input_example, # Auto-infers complex nested schema
)
Input Examples in Detail
Input examples serve multiple important purposes beyond signature inference:
Benefits of Input Examples
- Signature Inference: Automatically generate model signatures
- Model Validation: Verify model works during logging
- Dependency Detection: Help identify required packages
- Documentation: Show developers proper input format
- Deployment Testing: Validate REST endpoint payload format
Input Example Formats
- DataFrame Examples
- Tensor Examples
- JSON Examples
- Examples with Parameters
import pandas as pd
# Single record example
single_record = pd.DataFrame(
[{"sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2}]
)
# Multiple records example
batch_example = pd.DataFrame(
[
{"feature_1": 1.0, "feature_2": "A"},
{"feature_1": 2.0, "feature_2": "B"},
{"feature_1": 3.0, "feature_2": "C"},
]
)
# Log model with DataFrame example
mlflow.sklearn.log_model(model, name="model", input_example=single_record)
import numpy as np
# Image batch example (MNIST-style)
image_batch = np.random.randint(0, 255, size=(3, 28, 28, 1), dtype=np.uint8)
# Multi-input dictionary
multi_input = {
"image": np.random.random((2, 224, 224, 3)),
"metadata": np.array([[1.0, 2.0], [3.0, 4.0]]),
}
# Sparse matrix example
from scipy.sparse import csr_matrix
sparse_example = csr_matrix([[1, 0, 2], [0, 0, 3]])
# Log model with tensor example
mlflow.tensorflow.log_model(model, name="model", input_example=image_batch)
# Dictionary example
dict_example = {
"messages": [
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello!"},
],
"temperature": 0.7,
}
# List example
list_example = [
{"text": "First document", "category": "news"},
{"text": "Second document", "category": "sports"},
]
# Simple scalar
scalar_example = "What is the capital of France?"
# Log model with JSON example
mlflow.langchain.log_model(model, name="model", input_example=dict_example)
# Combine input data with parameters using tuple
input_data = "Translate to Spanish: Good morning"
params = {"temperature": 0.2, "max_length": 50, "do_sample": True}
# Create tuple for logging
input_example = (input_data, params)
# Log model with parameters
mlflow.transformers.log_model(
model, name="translation_model", input_example=input_example
)
# At inference time
loaded_model = mlflow.pyfunc.load_model(model_uri)
# Use default parameters
result1 = loaded_model.predict(input_data)
# Override parameters
result2 = loaded_model.predict(input_data, params={"temperature": 0.1})
Model Serving and Deployment
Serving Input Examples
MLflow automatically generates serving-compatible examples:
# When you log a model with input_example
input_example = {"question": "What is MLflow?"}
with mlflow.start_run():
model_info = mlflow.pyfunc.log_model(
python_model=MyModel(), name="model", input_example=input_example
)
# MLflow creates two files:
# 1. input_example.json - Original format
# 2. serving_input_example.json - REST API format
Generated Files:
| File | Content | Purpose |
|---|---|---|
input_example.json | {"question": "What is MLflow?"} | Original input format |
serving_input_example.json | {"inputs": {"question": "What is MLflow?"}} | REST endpoint format |
Validating Serving Examples
Test your model before deployment:
from mlflow.models.utils import load_serving_example
from mlflow.models import validate_serving_input
# Load serving example
serving_example = load_serving_example(model_info.model_uri)
# Validate it works
result = validate_serving_input(model_info.model_uri, serving_example)
print(f"Validation result: {result}")
# Test with local server
# mlflow models serve --model-uri <model_uri>
# curl -X POST -H "Content-Type: application/json" \
# -d '<serving_example>' http://localhost:5000/invocations
Signature Playground and Examples
Explore signature behavior with our interactive examples:
Download Signature Examples NotebookOr view examples directly: Signature Examples Notebook
Quick Reference Examples
- Basic Examples
- DataFrame Examples
- Tensor Examples
from mlflow.models import infer_signature
# Simple dictionary
simple_dict = {"name": "Alice", "age": 30, "active": True}
print(infer_signature(simple_dict))
# → Schema: [name: string, age: long, active: boolean]
# With optional fields
optional_fields = [
{"name": "Alice", "email": "alice@example.com"},
{"name": "Bob", "email": None}, # email becomes optional
]
print(infer_signature(optional_fields))
# → Schema: [name: string, email: string (optional)]
# Arrays and nested objects
complex_data = {
"user": {"id": 123, "tags": ["premium", "beta"]},
"scores": [0.8, 0.9, 0.7],
}
print(infer_signature(complex_data))
# → Nested schema with arrays and objects
import pandas as pd
# Basic DataFrame
df = pd.DataFrame(
{
"feature_1": [1.0, 2.0, 3.0],
"feature_2": ["A", "B", "C"],
"feature_3": [True, False, True],
}
)
print(infer_signature(df))
# → Column-based schema
# With missing values (creates optional columns)
df_optional = pd.DataFrame(
{"required_col": [1, 2, 3], "optional_col": [1.0, None, 3.0]} # Contains None
)
print(infer_signature(df_optional))
# → optional_col marked as optional
# Mixed data types
df_mixed = pd.DataFrame(
{
"numbers": [1, 2, 3],
"arrays": [[1, 2], [3, 4], [5, 6]], # Lists in DataFrame
"objects": [{"a": 1}, {"b": 2}, {"c": 3}], # Dicts in DataFrame
}
)
print(infer_signature(df_mixed))
# → Complex schema with Array and Object types
import numpy as np
# Simple tensor
tensor_2d = np.array([[1, 2, 3], [4, 5, 6]])
print(infer_signature(tensor_2d))
# → Tensor(int64, (-1, 3))
# Image-like tensor
image_batch = np.random.randint(0, 255, (10, 28, 28, 1), dtype=np.uint8)
print(infer_signature(image_batch))
# → Tensor(uint8, (-1, 28, 28, 1))
# Multiple tensors
multi_tensor = {
"image": np.random.random((5, 224, 224, 3)),
"mask": np.random.randint(0, 2, (5, 224, 224, 1)),
}
print(infer_signature(multi_tensor))
# → Schema with multiple tensor specs
Best Practices and Tips
Development Workflow
Always Include Input Examples
# ✅ Good: Always provide examples
mlflow.sklearn.log_model(model, name="model", input_example=X_sample)
# ❌ Avoid: Logging without examples
mlflow.sklearn.log_model(model, name="model") # No signature or validation
Test Your Signatures
# Validate signature works as expected
signature = infer_signature(X_test, y_pred)
loaded_model = mlflow.pyfunc.load_model(model_uri)
# Test with your signature
try:
result = loaded_model.predict(X_test)
print("✅ Signature validation passed")
except Exception as e:
print(f"❌ Signature issue: {e}")
Performance Considerations
For Large DataFrames:
# Use a representative sample for input_example
large_df = pd.DataFrame(...) # 1M+ rows
sample_df = large_df.sample(n=100, random_state=42) # Representative sample
mlflow.sklearn.log_model(model, name="model", input_example=sample_df)
For Complex Objects:
# Provide minimal but representative examples
minimal_example = {
"required_field": "example_value",
"optional_field": None, # Shows field is optional
"array_field": ["sample"], # Shows it's an array
}
Common Pitfalls
Integer Handling:
# ❌ Problem: Integers with NaN become floats
df = pd.DataFrame({"int_col": [1, 2, None]}) # Type becomes float64
# ✅ Solution: Use consistent types
df = pd.DataFrame({"int_col": [1.0, 2.0, None]}) # Explicit float64
Nested Structure Consistency:
# ❌ Problem: Inconsistent nesting
inconsistent = [
{"level1": {"level2": "value"}},
{"level1": "direct_value"}, # Different structure
]
# ✅ Solution: Consistent structure
consistent = [
{"level1": {"level2": "value1"}},
{"level1": {"level2": "value2"}}, # Same structure
]
Type Hints for PythonModel (MLflow 2.20.0+):
from typing import Dict, List
class TypedModel(mlflow.pyfunc.PythonModel):
def predict(self, context, model_input: List[Dict[str, str]]) -> List[str]:
# Signature automatically inferred from type hints!
return [item["text"].upper() for item in model_input]
Troubleshooting
Common Error Messages
"Required input field missing":
This error occurs when your model expects a required field that's not present in the input data.
# Example: Model expects field "age" but input only has "name"
input_data = {"name": "Alice"} # Missing required "age" field
Solution: Include all required fields in your input data, or mark the field as optional in your signature by including None values in your input example.
"Cannot convert type X to type Y":
This happens when you try to pass data of one type where the signature expects another type.
# Example: Trying to pass string where integer expected
input_data = {"score": "85"} # String value
# But signature expects: {"score": 85} # Integer value
Solution: Fix your input data types to match the signature, or update the signature if the type change is intentional.
"Tensor shape mismatch":
This error occurs when tensor inputs don't match the expected shape defined in the signature.
# Example: Model expects shape (None, 784) but got (None, 28, 28)
input_tensor = np.random.random((10, 28, 28)) # Wrong shape
# But signature expects: (10, 784) # Flattened shape
Solution: Reshape your input data to match the expected dimensions, or update the signature if the shape requirements have changed.
Debugging Signatures
Use these techniques to diagnose signature-related issues:
# Inspect existing model signature
from mlflow.models.model import get_model_info
model_info = get_model_info(model_uri)
print("Current signature:")
print(model_info.signature)
# Compare with inferred signature
inferred = infer_signature(your_input_data)
print("Inferred signature:")
print(inferred)
# Check compatibility
if model_info.signature != inferred:
print("⚠️ Signatures don't match - consider updating")
Additional Resources
- Signature Examples Notebook - Interactive examples
- Model API Documentation - Complete API reference
- Deployment Guide - Using signatures in production
- MLflow Model Format - Technical specification