Optimize Prompts (Experimental)
MLflow allows you to plug your prompts into advanced prompt optimization techniques through MLflow's unified interface using the mlflow.genai.optimize_prompt() API.
This feature helps you improve your prompts automatically by leveraging evaluation metrics and labeled data. Currently, DSPy's MIPROv2 algorithm is supported by this API.
- Unified Interface: Access to the state-of-the-art prompt optimization algorithms through a neutral interface.
- Prompt Management: Integrate with MLflow Prompt Registry to gain reusability, version control and lineage.
- Evaluation: Evaluate prompt performance comprehensively with MLflow's evaluation features.
Optimization Overview
In order to use mlflow.genai.optimize_prompt() API, you need to prepare the following:
| Component | Definition | Example |
|---|---|---|
| Registered Prompt | A prompt registered in MLflow. See Prompt Management for how to register a prompt. | |
| Scorer Objects | A set of Scorer objects that evaluate the quality of the prompt. See mlflow.genai.scorer() for how to define a custom scorer. | |
| Training(+Validation) Data | A set of training data and optionally validation data containing inputs and expected outputs. | [{"inputs": {"question": "2+2"}, "expectations": {"answer": "4"}}, {"inputs": {"question": "2+3"}, "expectations": {"answer": "5"}}] |
Getting Started
Here's a simple example of optimizing a question-answering prompt:
As a prerequisite, you need to install DSPy.
$ pip install dspy>=2.6.0 mlflow>=3.1.0
Then, run the following code to register the initial prompt and optimize it.
import os
from typing import Any
import mlflow
from mlflow.genai.scorers import scorer
from mlflow.genai.optimize import OptimizerConfig, LLMParams
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>"
# Define a custom scorer function to evaluate prompt performance with the @scorer decorator.
# The scorer function for optimization can take inputs, outputs, and expectations.
@scorer
def exact_match(expectations: dict[str, Any], outputs: dict[str, Any]) -> bool:
return expectations["answer"] == outputs["answer"]
# Register the initial prompt
initial_template = """
Answer to this math question: {{question}}.
Return the result in a JSON string in the format of {"answer": "xxx"}.
"""
prompt = mlflow.register_prompt(
name="math",
template=initial_template,
)
# The data can be a list of dictionaries, a pandas DataFrame, or an mlflow.genai.EvaluationDataset
# It needs to contain inputs and expectations where each row is a dictionary.
train_data = [
{
"inputs": {"question": "Given that $y=3$, evaluate $(1+y)^y$."},
"expectations": {"answer": "64"},
},
{
"inputs": {
"question": "The midpoint of the line segment between $(x,y)$ and $(-9,1)$ is $(3,-5)$. Find $(x,y)$."
},
"expectations": {"answer": "(15,-11)"},
},
{
"inputs": {
"question": "What is the value of $b$ if $5^b + 5^b + 5^b + 5^b + 5^b = 625^{(b-1)}$? Express your answer as a common fraction."
},
"expectations": {"answer": "\\frac{5}{3}"},
},
{
"inputs": {"question": "Evaluate the expression $a^3\\cdot a^2$ if $a= 5$."},
"expectations": {"answer": "3125"},
},
{
"inputs": {"question": "Evaluate $\\lceil 8.8 \\rceil+\\lceil -8.8 \\rceil$."},
"expectations": {"answer": "17"},
},
]
eval_data = [
{
"inputs": {
"question": "The sum of 27 consecutive positive integers is $3^7$. What is their median?"
},
"expectations": {"answer": "81"},
},
{
"inputs": {"question": "What is the value of $x$ if $x^2 - 10x + 25 = 0$?"},
"expectations": {"answer": "5"},
},
{
"inputs": {
"question": "If $a\\ast b = 2a+5b-ab$, what is the value of $3\\ast10$?"
},
"expectations": {"answer": "26"},
},
{
"inputs": {
"question": "Given that $-4$ is a solution to $x^2 + bx -36 = 0$, what is the value of $b$?"
},
"expectations": {"answer": "-5"},
},
]
# Optimize the prompt
result = mlflow.genai.optimize_prompt(
target_llm_params=LLMParams(model_name="openai/gpt-4.1-mini"),
prompt=prompt,
train_data=train_data,
eval_data=eval_data,
scorers=[exact_match],
optimizer_config=OptimizerConfig(
num_instruction_candidates=8,
max_few_show_examples=2,
),
)
# The optimized prompt is automatically registered as a new version
print(result.prompt.uri)
In the example above the average performance score increased from 0 to 0.5. After the optimization process is completed, you can visit the MLflow Prompt Registry page and see the optimized prompt.
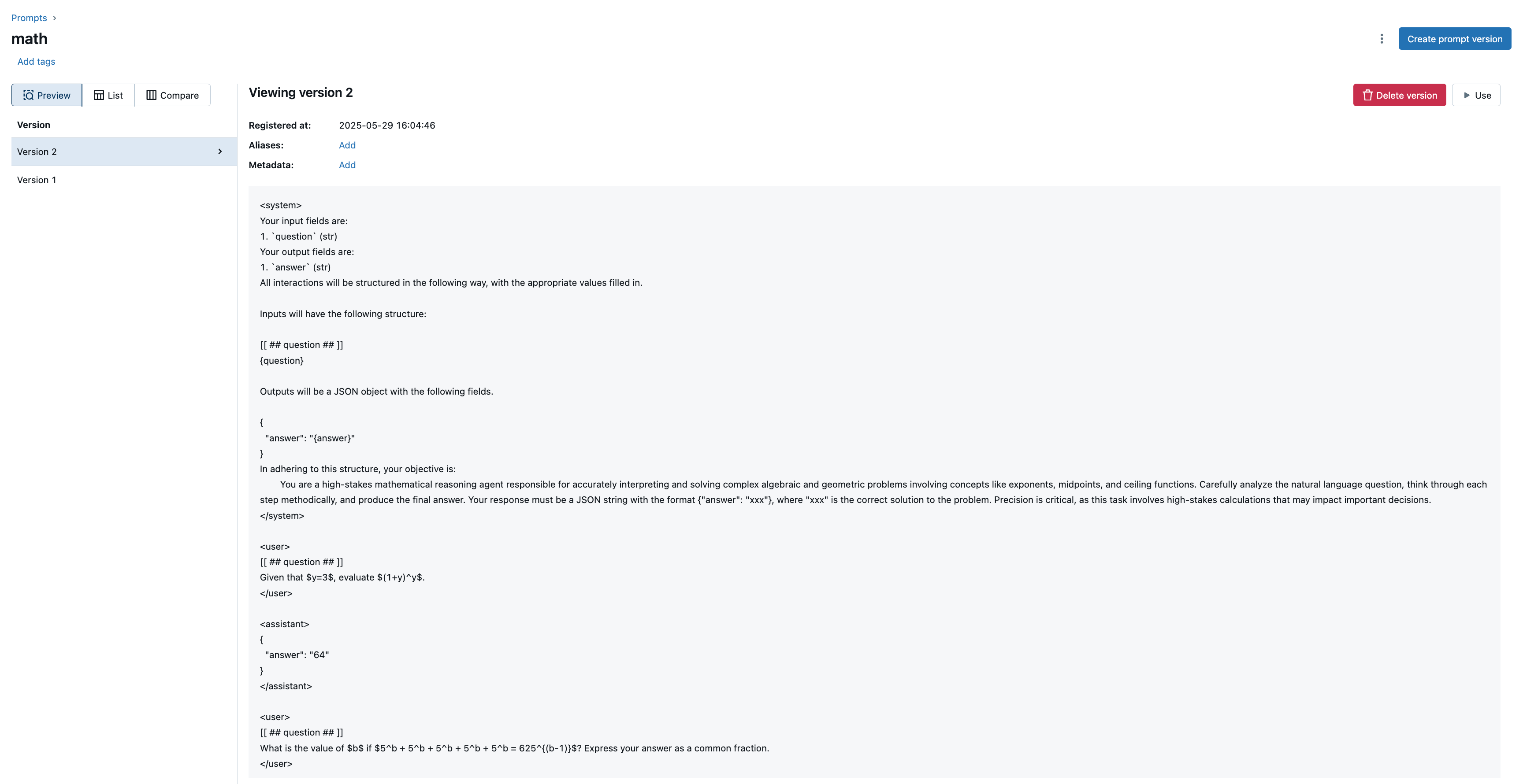
Note that the optimized prompt of mlflow.genai.optimize_prompt() expects the output to be a JSON string.
Therefore, you need to parse the output using json.loads in your application. See Load and Use the Prompt for how to load the optimized prompt.
import mlflow
import json
import openai
def predict(question: str, prompt_uri: str) -> str:
prompt = mlflow.load_prompt(prompt_uri)
content = prompt.format(question=question)
completion = openai.chat.completions.create(
model="gpt-4.1-mini",
messages=[{"role": "user", "content": content}],
temperature=0.1,
)
return json.loads(completion.choices[0].message.content)["answer"]
Configuration
You can customize the optimization process using OptimizerConfig, which includes the following parameters:
- num_instruction_candidates: The number of candidate instructions to try. Default: 6
- max_few_show_examples: The maximum number of examples to show in few-shot demonstrations. Default: 6
- optimizer_llm: The LLM to use for optimization. Default: None (uses target LLM)
- verbose: Whether to show optimizer logs during optimization. Default: False
- autolog: Whether to log the optimization parameters, datasets and metrics. If set to True, a MLflow run is automatically created to store them. Default: False
See mlflow.genai.OptimizerConfig() for more details.
FAQ
What are the supported Dataset formats?
The training and evaluation data for the mlflow.genai.optimize_prompt() API can be a list of dictionaries, a pandas DataFrame, a spark DataFrame, or an mlflow.genai.EvaluationDataset.
In any case, the data needs to contain inputs and expectations columns that contains a dictionary of input fields and expected output fields.
Each inputs or expectations dictionary can contain primitive types, lists, nested dictionaries, and Pydantic models. Data types are inferred from the first row of the dataset.
# ✅ OK
[
{
"inputs": {"question": "What is the capital of France?"},
"expectations": {"answer": "Paris"},
},
]
# ✅ OK
[
{
"inputs": {"question": "What are the three largest cities of Japan?"},
"expectations": {"answer": ["Tokyo", "Osaka", "Nagoya"]},
},
]
# ✅ OK
from pydantic import BaseModel
class Country(BaseModel):
name: str
capital: str
population: int
[
{
"inputs": {"question": "What is the capital of France?"},
"expectations": {
"answer": Country(name="France", capital="Paris", population=68000000)
},
},
]
# ❌ NG
[
{
"inputs": "What is the capital of France?",
"expectations": "Paris",
},
]
How to combine multiple scorers?
While the mlflow.genai.optimize_prompt() API accepts multiple scorers, the optimizer needs to combine them into a single score during the optimization process.
By default, the optimizer computes the total score of all scorers with numeric or boolean values.
If you want to use a custom aggregation function or use scorers that return non-numeric values, you can pass a custom aggregation function to the objective parameter.
@scorer
def safeness(outputs: dict[str, Any]) -> bool:
return "death" not in outputs["answer"].lower()
@scorer
def relevance(expectations: dict[str, Any], outputs: dict[str, Any]) -> bool:
return expectations["answer"] in outputs["answer"]
def objective(scores: dict[str, Any]) -> float:
if not scores["safeness"]:
return -1
return scores["relevance"]
result = mlflow.genai.optimize_prompt(
target_llm_params=LLMParams(model_name="openai/gpt-4.1-mini"),
prompt=prompt,
train_data=train_data,
eval_data=eval_data,
scorers=[safeness, relevance],
objective=objective,
)