Evaluating Prompts
Combining MLflow Prompt Registry with MLflow LLM Evaluation enables you to evaluate prompt performance across different models and datasets, and track the evaluation results in a centralized registry. You can also inspect model outputs from the traces logged during evaluation to understand how the model responds to different prompts.
- Effective Evaluation: `MLflow's LLM Evaluation API provides a simple and consistent way to evaluate prompts across different models and datasets without writing boilerplate code.
- Compare Results: Compare evaluation results with ease in the MLflow UI.
- Tracking Results: Track evaluation results in MLflow Experiment to maintain the history of prompt performance and different evaluation settings.
- Tracing: Inspect model behavior during inference deeply with traces generated during evaluation.
Quickstart
1. Install Required Libraries
First install MLflow and OpenAI SDK. If you use different LLM providers, install the corresponding SDK instead.
pip install mlflow>=2.21.0 openai -qU
Also set OpenAI API key (or any other LLM providers e.g. Anthropic).
import os
from getpass import getpass
os.environ["OPENAI_API_KEY"] = getpass("Enter your OpenAI API key: ")
1. Create a Prompt
- UI
- Python
- Run
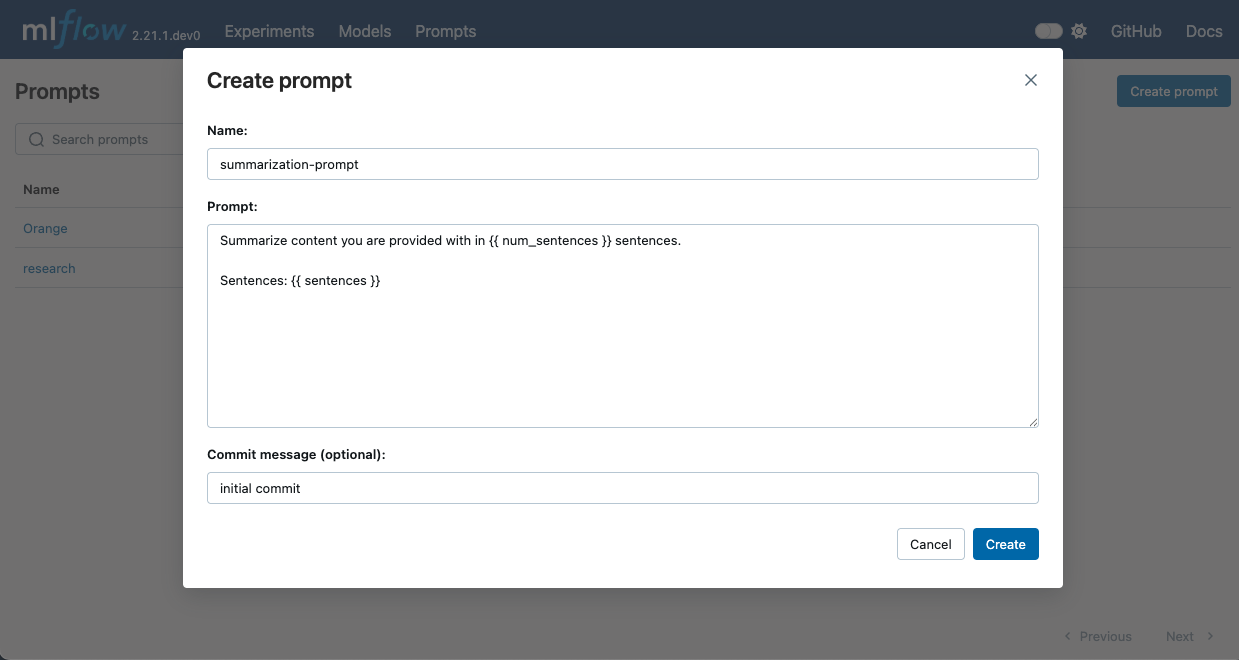
mlflow uiin your terminal to start the MLflow UI. - Navigate to the Prompts tab in the MLflow UI.
- Click on the Create Prompt button.
- Fill in the prompt details such as name, prompt template text, and commit message (optional).
- Click Create to register the prompt.
To create a new prompt using the Python API, use mlflow.register_prompt() API:
import mlflow
# Use double curly braces for variables in the template
initial_template = """\
Summarize content you are provided with in {{ num_sentences }} sentences.
Sentences: {{ sentences }}
"""
# Register a new prompt
prompt = mlflow.register_prompt(
name="summarization-prompt",
template=initial_template,
# Optional: Provide a commit message to describe the changes
commit_message="Initial commit",
)
# The prompt object contains information about the registered prompt
print(f"Created prompt '{prompt.name}' (version {prompt.version})")
2. Prepare Evaluation Data
Below, we create a small summarization dataset for demonstration purposes.
import pandas as pd
eval_data = pd.DataFrame(
{
"inputs": [
"Artificial intelligence has transformed how businesses operate in the 21st century. Companies are leveraging AI for everything from customer service to supply chain optimization. The technology enables automation of routine tasks, freeing human workers for more creative endeavors. However, concerns about job displacement and ethical implications remain significant. Many experts argue that AI will ultimately create more jobs than it eliminates, though the transition may be challenging.",
"Climate change continues to affect ecosystems worldwide at an alarming rate. Rising global temperatures have led to more frequent extreme weather events including hurricanes, floods, and wildfires. Polar ice caps are melting faster than predicted, contributing to sea level rise that threatens coastal communities. Scientists warn that without immediate and dramatic reductions in greenhouse gas emissions, many of these changes may become irreversible. International cooperation remains essential but politically challenging.",
"The human genome project was completed in 2003 after 13 years of international collaborative research. It successfully mapped all of the genes of the human genome, approximately 20,000-25,000 genes in total. The project cost nearly $3 billion but has enabled countless medical advances and spawned new fields like pharmacogenomics. The knowledge gained has dramatically improved our understanding of genetic diseases and opened pathways to personalized medicine. Today, a complete human genome can be sequenced in under a day for about $1,000.",
"Remote work adoption accelerated dramatically during the COVID-19 pandemic. Organizations that had previously resisted flexible work arrangements were forced to implement digital collaboration tools and virtual workflows. Many companies reported surprising productivity gains, though concerns about company culture and collaboration persisted. After the pandemic, a hybrid model emerged as the preferred approach for many businesses, combining in-office and remote work. This shift has profound implications for urban planning, commercial real estate, and work-life balance.",
"Quantum computing represents a fundamental shift in computational capability. Unlike classical computers that use bits as either 0 or 1, quantum computers use quantum bits or qubits that can exist in multiple states simultaneously. This property, known as superposition, theoretically allows quantum computers to solve certain problems exponentially faster than classical computers. Major technology companies and governments are investing billions in quantum research. Fields like cryptography, material science, and drug discovery are expected to be revolutionized once quantum computers reach practical scale.",
],
"targets": [
"AI has revolutionized business operations through automation and optimization, though ethical concerns about job displacement persist alongside predictions that AI will ultimately create more employment opportunities than it eliminates.",
"Climate change is causing accelerating environmental damage through extreme weather events and melting ice caps, with scientists warning that without immediate reduction in greenhouse gas emissions, many changes may become irreversible.",
"The Human Genome Project, completed in 2003, mapped approximately 20,000-25,000 human genes at a cost of $3 billion, enabling medical advances, improving understanding of genetic diseases, and establishing the foundation for personalized medicine.",
"The COVID-19 pandemic forced widespread adoption of remote work, revealing unexpected productivity benefits despite collaboration challenges, and resulting in a hybrid work model that impacts urban planning, real estate, and work-life balance.",
"Quantum computing uses qubits existing in multiple simultaneous states to potentially solve certain problems exponentially faster than classical computers, with major investment from tech companies and governments anticipating revolutionary applications in cryptography, materials science, and pharmaceutical research.",
],
}
)
3. Define Prediction Function
Define a function that takes a DataFrame of inputs and returns a list of predictions.
MLflow will pass the input columns (inputs only in this example) to the function. The output string will be compared with the targets column to evaluate the model.
import mlflow
import openai
def predict(data: pd.DataFrame) -> list[str]:
predictions = []
prompt = mlflow.load_prompt("prompts:/summarization-prompt/1")
for _, row in data.iterrows():
# Fill in variables in the prompt template
content = prompt.format(sentences=row["inputs"], num_sentences=1)
completion = openai.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": content}],
temperature=0.1,
)
predictions.append(completion.choices[0].message.content)
return predictions
4. Run Evaluation
Run the mlflow.evaluate() API to evaluate the model with the prepared data and prompt. In this example, we will use the following two built-in metrics.
with mlflow.start_run(run_name="prompt-evaluation"):
mlflow.log_param("model", "gpt-4o-mini")
mlflow.log_param("temperature", 0.1)
results = mlflow.evaluate(
model=predict,
data=eval_data,
targets="targets",
extra_metrics=[
mlflow.metrics.latency(),
# Specify GPT4 as a judge model for answer similarity. Other models such as Anthropic,
# Bedrock, Databricks, are also supported.
mlflow.metrics.genai.answer_similarity(model="openai:/gpt-4"),
],
)
There are numbers of built-in metrics available in MLflow for evaluating LLMs. You can also define custom metrics including LLM-as-a-Judge. Refer to the LLM Evaluation Metrics for more details.
5. View Results
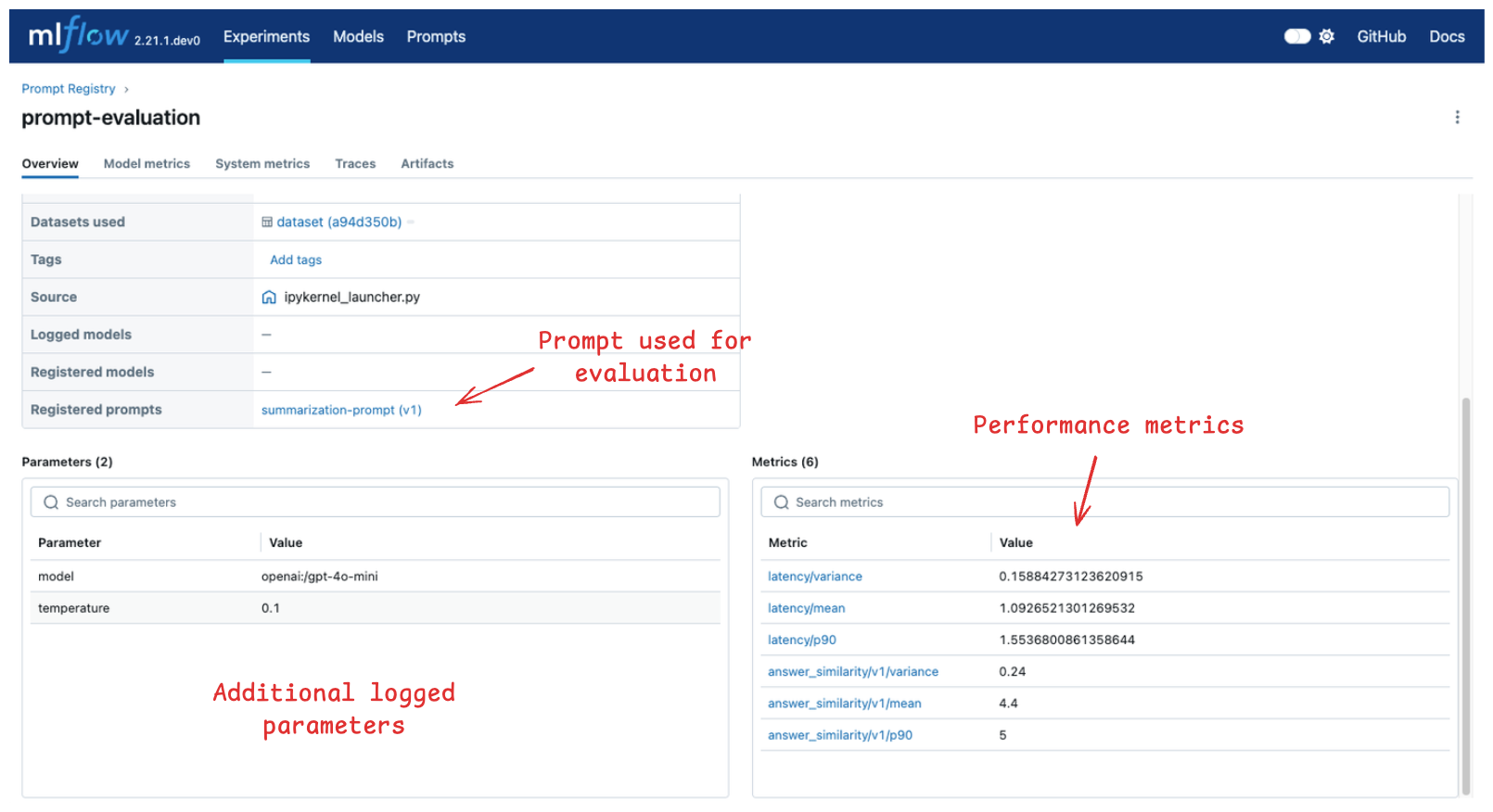
You can view the evaluation results in the MLflow UI. Navigate to the Experiments tab and click on the evaluation run (prompt-evaluation in this example) to view the evaluation result.
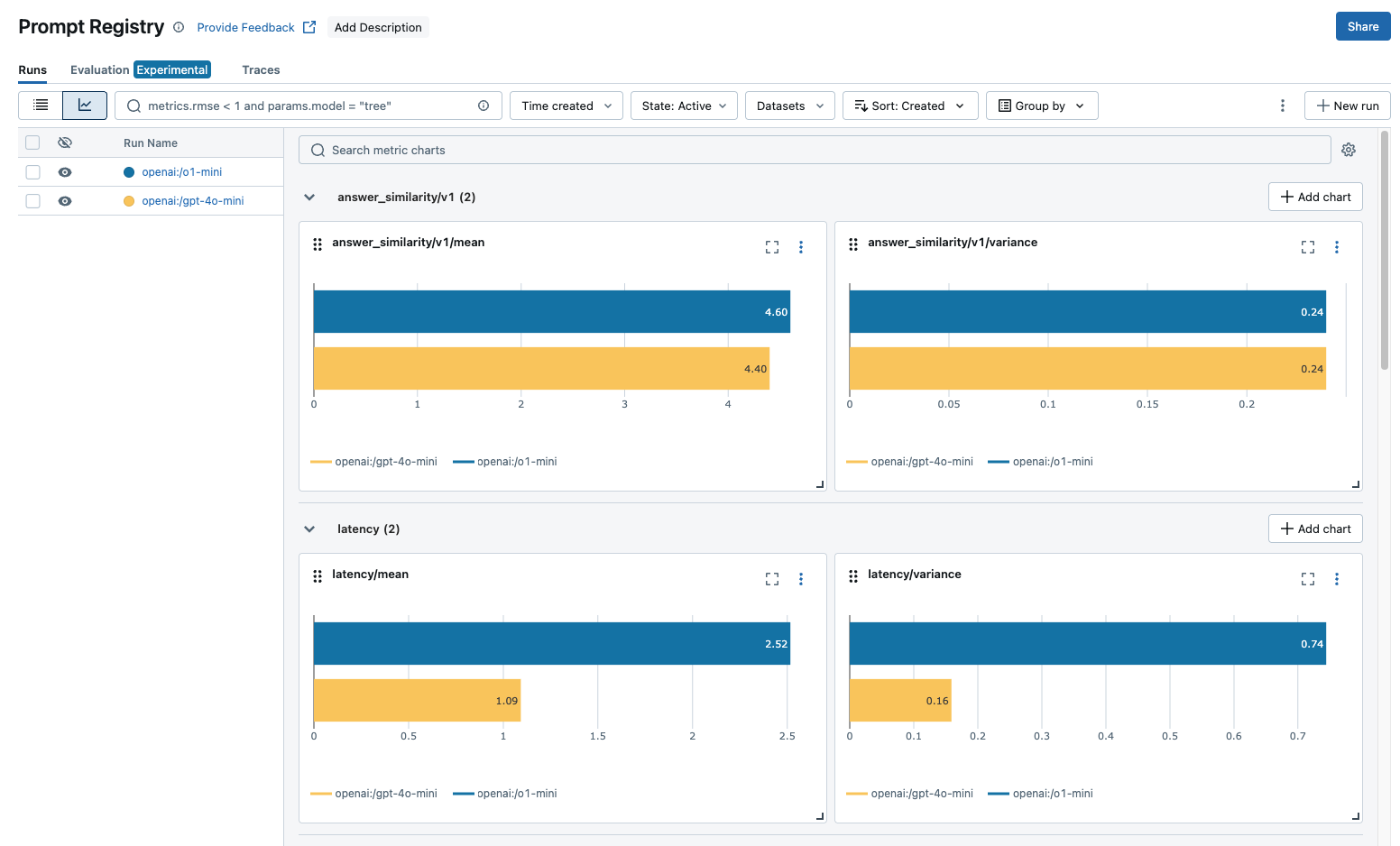
If you have multiple Evaluation Runs, you can compare the metrics across runs in the chart view.
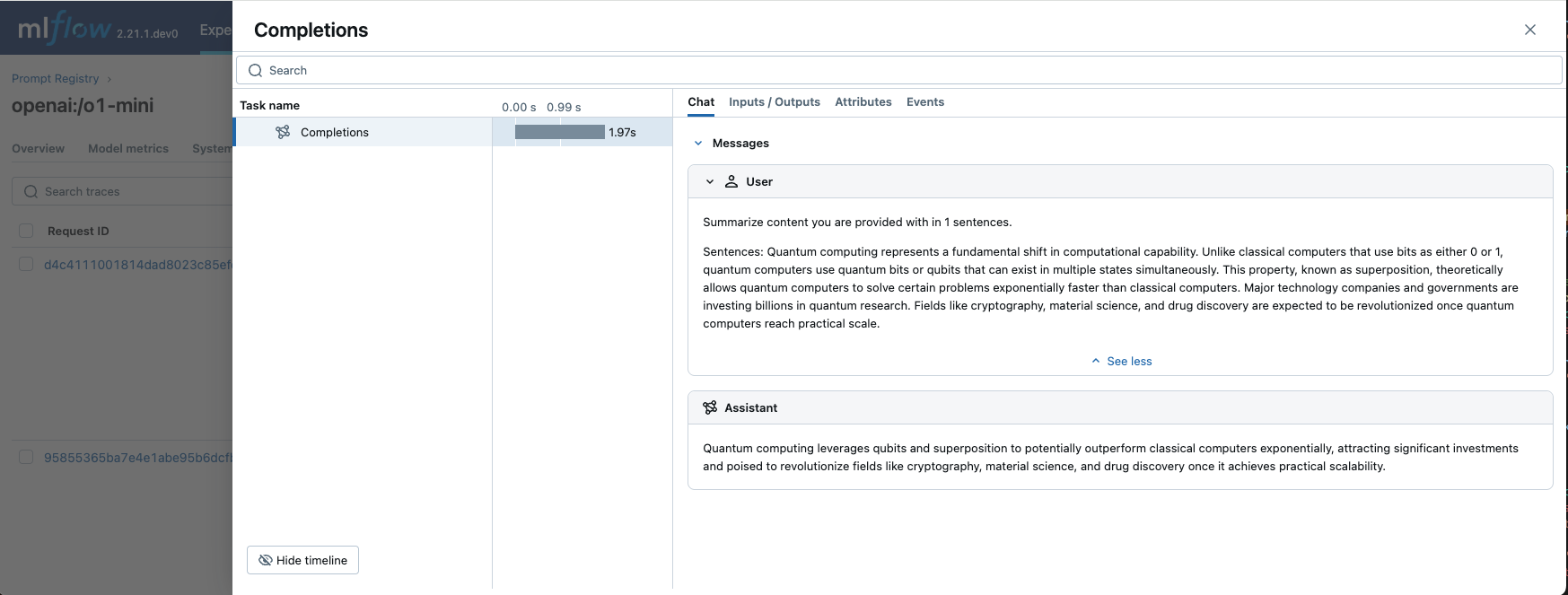
Moreover, you can navigate to the Traces tab in the evaluation run page to show all input and output responses from the LLM during evaluation, to understand how the model responds to different prompts.