GenAI Agent Quickstart
Build and evaluate a LangChain-based chatbot with MLflow's comprehensive tracking and evaluation capabilities. This quickstart demonstrates prompt engineering, trace generation, and performance assessment using MLflow 3's GenAI features.
Prerequisites
Install Required Packages
This quickstart requires MLflow version 3.0 or higher for full GenAI functionality.
pip install --upgrade mlflow
pip install langchain-openai
Set OpenAI API Key
Configure your OpenAI API key to authenticate with OpenAI services:
export OPENAI_API_KEY=your_api_key_here
Overview
In this quickstart, you'll learn how to:
- Register and version control prompt templates
- Create a LangChain-based conversational agent
- Enable automatic trace logging for debugging
- Evaluate model performance with custom metrics
Let's build a simple IT support chatbot and track its development lifecycle with MLflow.
Step 1: Register a Prompt Template
Start by creating a versioned prompt template. This enables you to track prompt evolution and ensure reproducibility across experiments.
import mlflow
system_prompt = mlflow.genai.register_prompt(
name="chatbot_prompt",
template="You are a chatbot that can answer questions about IT. Answer this question: {{question}}",
commit_message="Initial version of chatbot",
)
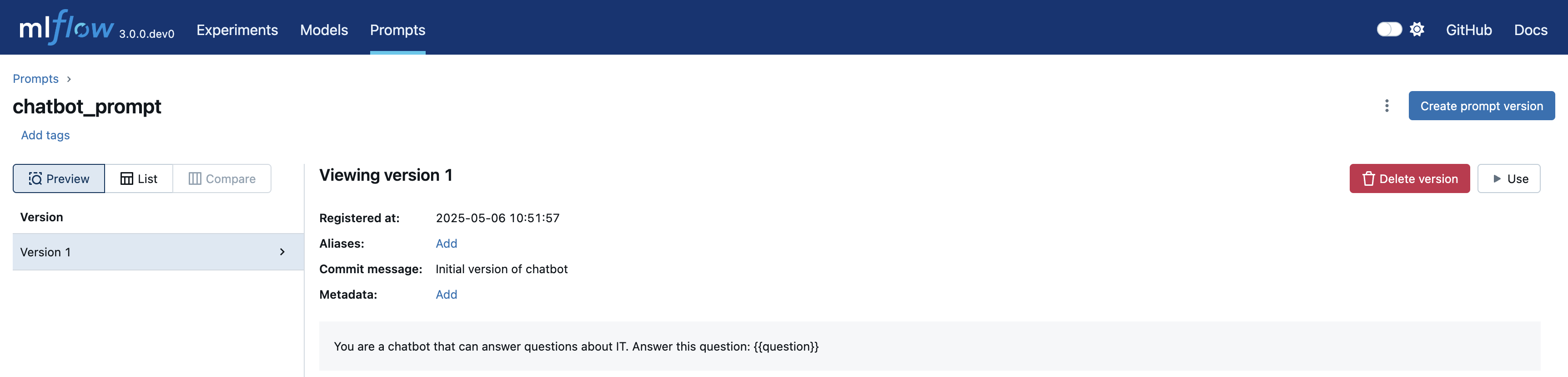
View Your Prompt in MLflow UI
Navigate to the Prompts tab to see your registered prompt:
Step 2: Build a LangChain Conversational Chain
Create a simple chain that combines your prompt template with OpenAI's chat model:
from langchain.schema.output_parser import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# Convert MLflow prompt to LangChain format
prompt = ChatPromptTemplate.from_template(system_prompt.to_single_brace_format())
# Build the chain: prompt → LLM → output parser
chain = prompt | ChatOpenAI(temperature=0.7) | StrOutputParser()
# Test the chain
question = "What is MLflow?"
print(chain.invoke({"question": question}))
# MLflow is an open-source platform for managing the end-to-end machine learning lifecycle...
Step 3: Enable Trace Observability
Set up automatic trace logging to monitor your model's behavior during development. This creates a linked history of all model interactions.
Configure Active Model and Autologging
# Set the active model for linking traces
mlflow.set_active_model(name="langchain_model")
# Enable autologging - all traces will be automatically linked to the active model
mlflow.langchain.autolog()
Generate Test Traces
Run multiple queries to generate traces for analysis:
questions = [
{"question": "What is MLflow Tracking and how does it work?"},
{"question": "What is Unity Catalog?"},
{"question": "What are user-defined functions (UDFs)?"},
]
outputs = []
for question in questions:
outputs.append(chain.invoke(question))
# Verify traces are linked to the active model
active_model_id = mlflow.get_active_model_id()
mlflow.search_traces(model_id=active_model_id)
Explore Traces in the UI
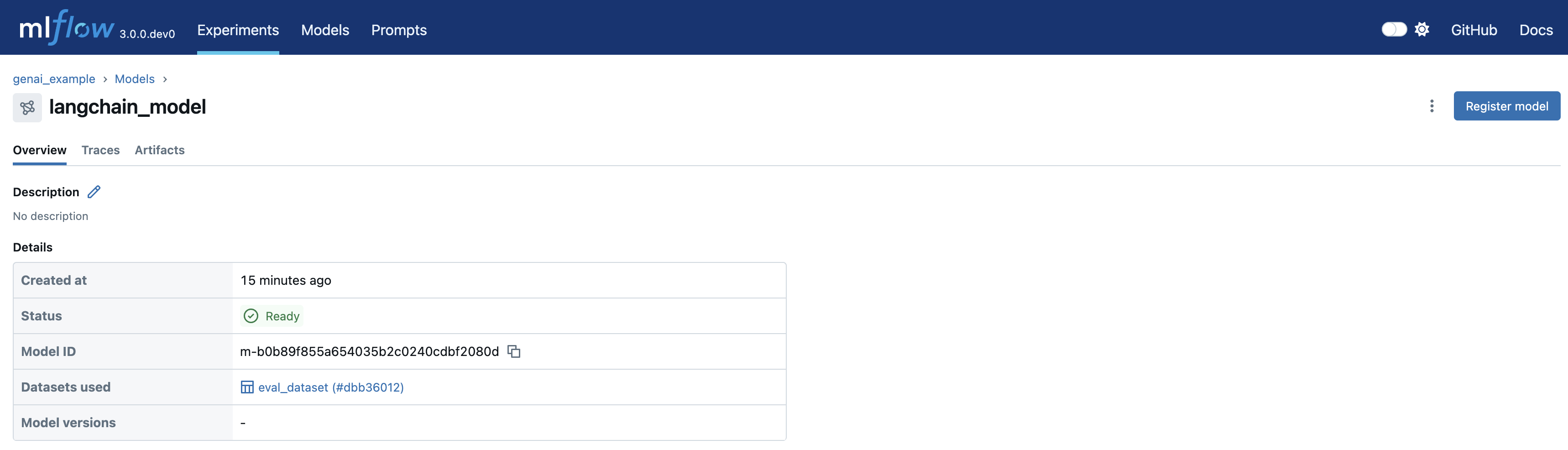
- View the Logged Model: Check the Models tab in your experiment:

- Access Model Details: Click on your model to view its unique
model_id:
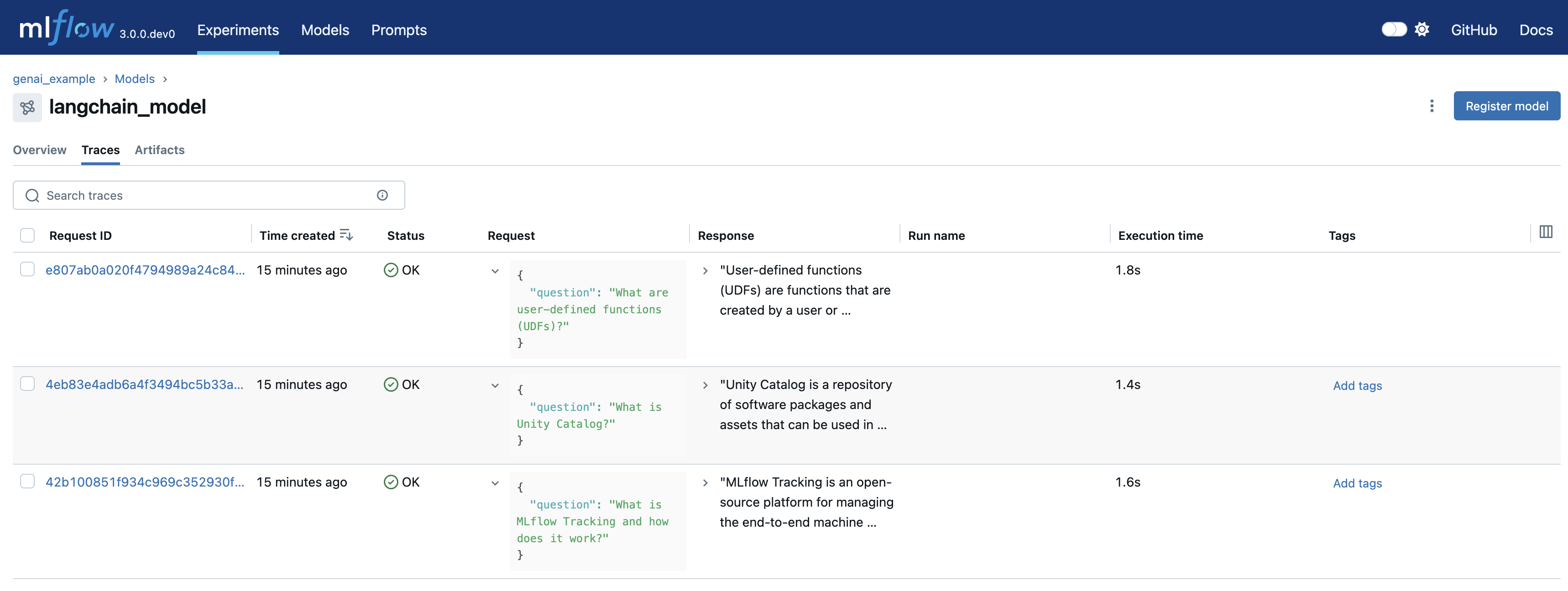
- Analyze Generated Traces: Navigate to the Traces tab to examine individual interactions:
Step 4: Evaluate Model Performance
Use MLflow's evaluation framework to assess your chatbot's accuracy and relevance against expected responses.
Run Evaluation with Custom Metrics
Evaluate your model using GenAI-specific metrics:
eval_df = pd.DataFrame(
{
"inputs": questions,
"expected_response": [
"""MLflow Tracking is a key component of the MLflow platform designed to record and manage machine learning experiments. It enables data scientists and engineers to log parameters, code versions, metrics, and artifacts in a systematic way, facilitating experiment tracking and reproducibility.
How It Works:
At the heart of MLflow Tracking is the concept of a run, which is an execution of a machine learning code. Each run can log the following:
Parameters: Input variables or hyperparameters used in the model (e.g., learning rate, number of trees). Metrics: Quantitative measures to evaluate the model's performance (e.g., accuracy, loss). Artifacts: Output files like models, datasets, or images generated during the run. Source Code: The version of the code or Git commit hash used. These logs are stored in a tracking server, which can be set up locally or on a remote server. The tracking server uses a backend storage (like a database or file system) to keep a record of all runs and their associated data.
Users interact with MLflow Tracking through its APIs available in multiple languages (Python, R, Java, etc.). By invoking these APIs in the code, you can start and end runs, and log data as the experiment progresses. Additionally, MLflow offers autologging capabilities for popular machine learning libraries, automatically capturing relevant parameters and metrics without manual code changes.
The logged data can be visualized using the MLflow UI, a web-based interface that displays all experiments and runs. This UI allows you to compare runs side-by-side, filter results, and analyze performance metrics over time. It aids in identifying the best models and understanding the impact of different parameters.
By providing a structured way to record experiments, MLflow Tracking enhances collaboration among team members, ensures transparency, and makes it easier to reproduce results. It integrates seamlessly with other MLflow components like Projects and Model Registry, offering a comprehensive solution for managing the machine learning lifecycle.""",
"""Unity Catalog is a feature in Databricks that allows you to create a centralized inventory of your data assets, such as tables, views, and functions, and share them across different teams and projects. It enables easy discovery, collaboration, and reuse of data assets within your organization.
With Unity Catalog, you can:
1. Create a single source of truth for your data assets: Unity Catalog acts as a central repository of all your data assets, making it easier to find and access the data you need.
2. Improve collaboration: By providing a shared inventory of data assets, Unity Catalog enables data scientists, engineers, and other stakeholders to collaborate more effectively.
3. Foster reuse of data assets: Unity Catalog encourages the reuse of existing data assets, reducing the need to create new assets from scratch and improving overall efficiency.
4. Enhance data governance: Unity Catalog provides a clear view of data assets, enabling better data governance and compliance.
Unity Catalog is particularly useful in large organizations where data is scattered across different teams, projects, and environments. It helps create a unified view of data assets, making it easier to work with data across different teams and projects.""",
"""User-defined functions (UDFs) in the context of Databricks and Apache Spark are custom functions that you can create to perform specific tasks on your data. These functions are written in a programming language such as Python, Java, Scala, or SQL, and can be used to extend the built-in functionality of Spark.
UDFs can be used to perform complex data transformations, data cleaning, or to apply custom business logic to your data. Once defined, UDFs can be invoked in SQL queries or in DataFrame transformations, allowing you to reuse your custom logic across multiple queries and applications.
To use UDFs in Databricks, you first need to define them in a supported programming language, and then register them with the SparkSession. Once registered, UDFs can be used in SQL queries or DataFrame transformations like any other built-in function.""",
],
"outputs": outputs,
}
)
from mlflow.genai.scorers import Correctness, RelevanceToQuery, Guidelines
# Run evaluation with GenAI metrics
result = mlflow.genai.evaluate(
data=eval_df,
scorers=[
Correctness(),
RelevanceToQuery(),
],
)
# View evaluation results
result.tables["eval_results"]
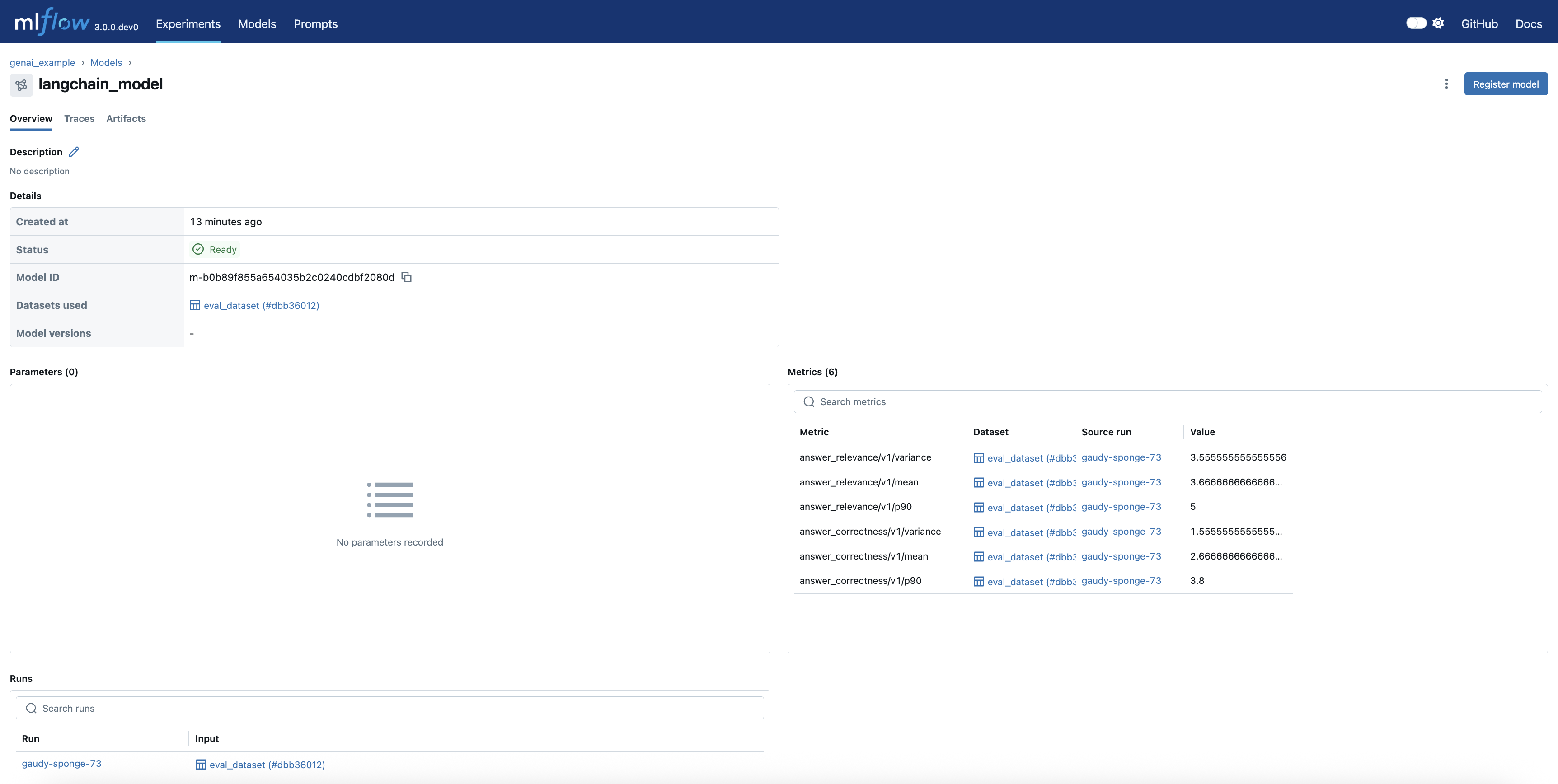
Analyze Evaluation Results
The evaluation generates detailed metrics with justifications:
Summary
You've successfully:
- ✅ Created a versioned prompt template for reproducibility
- ✅ Built a LangChain conversational agent with OpenAI
- ✅ Enabled automatic trace logging for complete observability
- ✅ Evaluated model performance with GenAI-specific metrics
Next Steps
- Experiment with Prompts: Try different prompt templates and compare their performance
- Add Custom Metrics: Create domain-specific evaluation metrics for your use case
- Deploy Your Model: Use MLflow's deployment capabilities to serve your chatbot
- Scale Evaluations: Run evaluations on larger datasets to ensure robustness