MLflow for GenAI Applications
Traditional software and ML tests aren't built for GenAI's free-form language, making it difficult for teams to measure and improve quality.
MLflow solves this by combining AI-powered metrics that reliably measure GenAI quality with comprehensive trace observability, enabling you to measure, improve, and monitor quality throughout your entire application lifecycle.
How MLflow Helps Measure and Improve GenAI Quality
MLflow helps you orchestrate a continuous improvement cycle that incorporates both user feedback and domain expert judgment. From development through production, you use consistent quality metrics (scorers) that are tuned to align with human expertise, ensuring your automated evaluation reflects real-world quality standards.
The Continuous Improvement Cycle
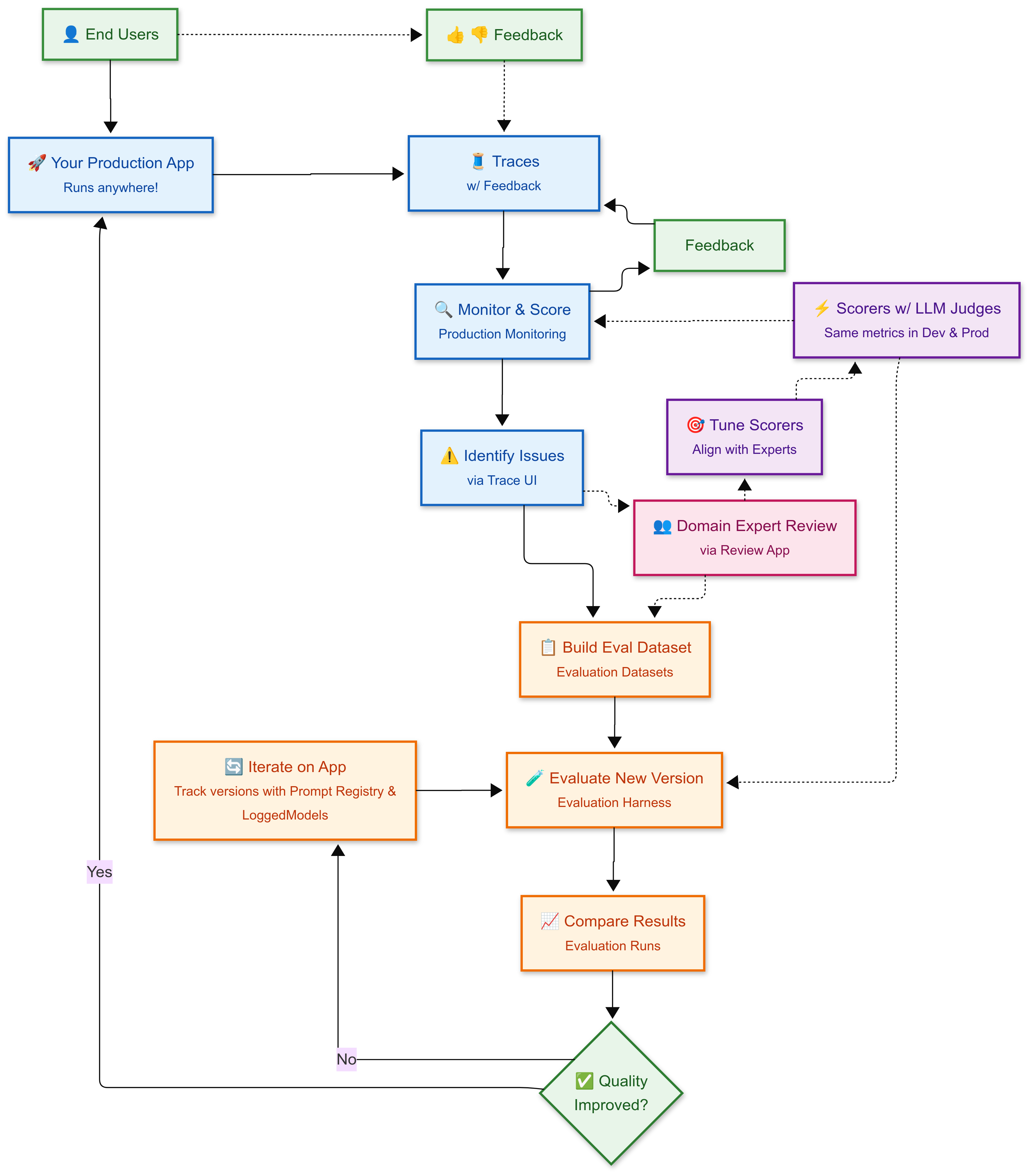
🚀 Production App
Your deployed GenAI app serves users and generates traces with detailed execution logs capturing all steps, inputs, and outputs for every interaction.
👍👎 User Feedback
End users provide feedback (thumbs up/down, ratings) that gets attached to each trace, helping identify quality issues in real-world usage.
3. 🔍 Monitor & Score
Production monitoring automatically runs LLM-judge based scorers on traces to assess quality, attaching scores and insights to each trace.
⚠️ Identify Issues
Use the Trace UI to find patterns in low-scoring traces through end user and LLM judge feedback.
📋 Build Eval Dataset
Curate both problematic traces and high-quality traces into evaluation datasets so you can fix issues while preserving what works well.
🎯 Tune Scorers
Optionally, use expert feedback to align your scorers and judges with human judgment, ensuring automated evaluation represents real quality standards.
🧪 Evaluate New Versions
Use the evaluation harness to test improved app versions against your evaluation datasets, applying the same scorers from monitoring to evaluate if quality improved or regressed. Track your work with version management and the prompt registry.
📈 Compare Results
Use evaluation runs generated by the evaluation harness to compare across versions and identify top performing configurations.
✅ Deploy or Iterate
If quality improves without regression, deploy to production. Otherwise, iterate on your solution and re-evaluate until you achieve your quality targets.
Why This Approach Works
🎯 Human-Aligned Metrics
Scorers are tuned to match domain expert judgment, ensuring automated evaluation reflects human quality standards rather than arbitrary metrics.
📊 Consistent Metrics
The same scorers work in both development and production, eliminating the disconnect between testing and real-world performance.
🌍 Real-World Data
Production traces become test cases, ensuring you fix actual user issues rather than hypothetical problems.
✅ Systematic Validation
Every change is tested against regression datasets before deployment, preventing quality degradation.
📈 Continuous Learning
Each cycle improves both your application and your evaluation datasets, creating a compounding effect on quality.
Getting Started with MLflow for GenAI
🚀 Quick Start
Follow our quickstart guides to:
- Set up tracing for your GenAI application
- Run your first evaluation
- Collect feedback from domain experts
- Enable production monitoring
🧠 Conceptual Understanding
Explore the data model to understand key abstractions:
- Traces - Detailed execution logs
- Experiments - Organized development workflows
Next Steps
🔑 Key Challenges
Understand the unique challenges of building production GenAI applications.
Learn more →