Manual Tracing
In addition to the Auto Tracing integrations, you can instrument your Python code using the MLflow Tracing SDK. This is especially useful when you need to instrument your custom Python code.
Decorator
The @mlflow.trace decorator allows you to create a span for any function. This approach provides a simple yet effective way to add tracing to your code with minimal effort:
- MLflow detects the parent-child relationships between functions, making it compatible with auto-tracing integrations.
- Captures exceptions during function execution and records them as span events.
- Automatically logs the function’s name, inputs, outputs, and execution time.
- Can be used alongside auto-tracing features, such as
mlflow.openai.autolog.
The @mlflow.trace decorator currently support the following types of functions:
| Function Type | Supported |
|---|---|
| Sync | ✅ |
| Async | ✅ (>= 2.16.0) |
| Generator | ✅ (>= 2.20.2) |
| Async Generator | ✅ (>= 2.20.2) |
Example
The following code is a minimum example of using the decorator for tracing Python functions.
import mlflow
@mlflow.trace(span_type="func", attributes={"key": "value"})
def add_1(x):
return x + 1
@mlflow.trace(span_type="func", attributes={"key1": "value1"})
def minus_1(x):
return x - 1
@mlflow.trace(name="Trace Test")
def trace_test(x):
step1 = add_1(x)
return minus_1(step1)
trace_test(4)
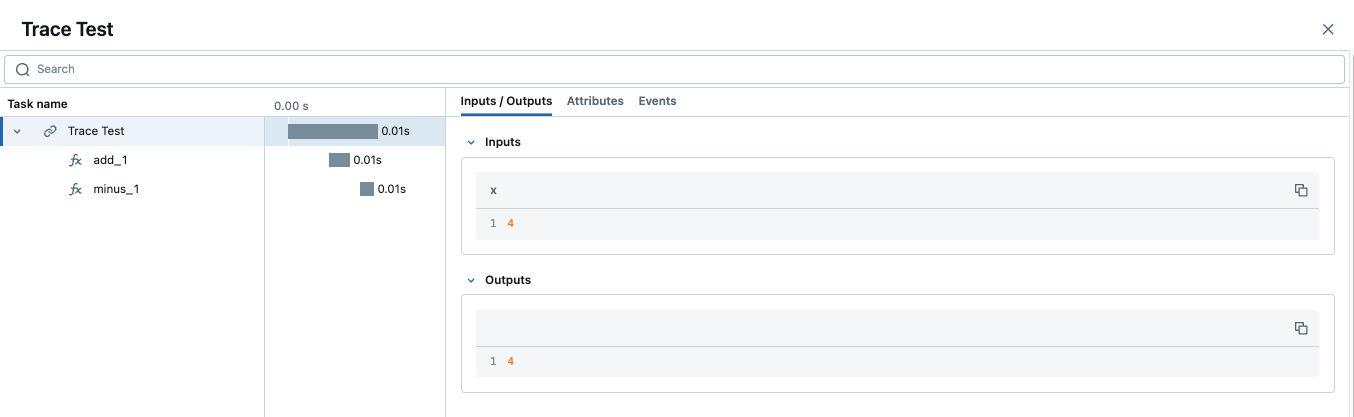
When a trace contains multiple spans with same name, MLflow appends an auto-incrementing suffix to them, such as _1, _2.
Customizing Spans
The @mlflow.trace decorator accepts following arguments to customize the span to be created:
nameparameter to override the span name from the default (the name of decorated function)span_typeparameter to set the type of span. Set either one of built-in Span Types or a string.attributesparameter to add custom attributes to the span.
@mlflow.trace(
name="call-local-llm", span_type=SpanType.LLM, attributes={"model": "gpt-4o-mini"}
)
def invoke(prompt: str):
return client.invoke(
messages=[{"role": "user", "content": prompt}], model="gpt-4o-mini"
)
Alternatively, you can update the span dynamically inside the function by using mlflow.get_current_active_span API.
@mlflow.trace(span_type=SpanType.LLM)
def invoke(prompt: str):
model_id = "gpt-4o-mini"
# Get the current span (created by the @mlflow.trace decorator)
span = mlflow.get_current_active_span()
# Set the attribute to the span
span.set_attributes({"model": model_id})
return client.invoke(messages=[{"role": "user", "content": prompt}], model=model_id)
Adding Trace Tags
Tags can be added to traces to provide additional metadata at the trace level. There are a few different ways to set tags on a trace. Please refer to the how-to guide for the other methods.
@mlflow.trace
def my_func(x):
mlflow.update_current_trace(tags={"fruit": "apple"})
return x + 1
Automatic Exception Handling
If an Exception is raised during processing of a trace-instrumented operation, an indication will be shown within the UI that the invocation was not
successful and a partial capture of data will be available to aid in debugging. Additionally, details about the Exception that was raised will be included
within Events of the partially completed span, further aiding the identification of where issues are occurring within your code.
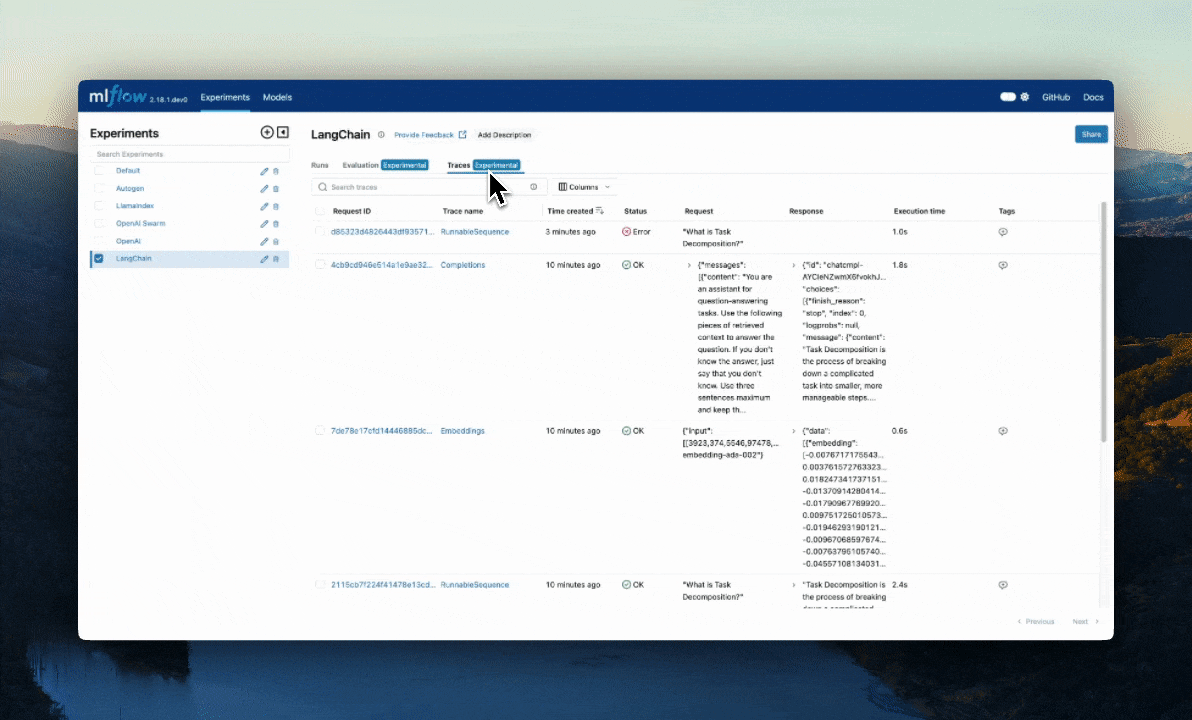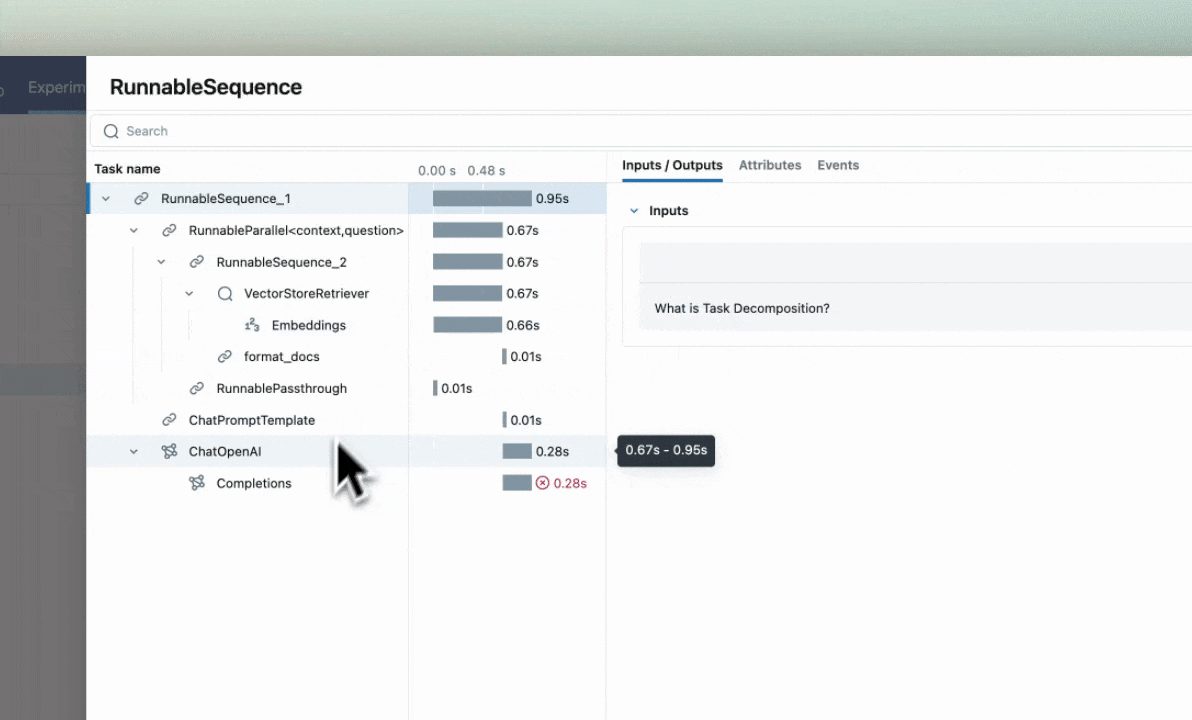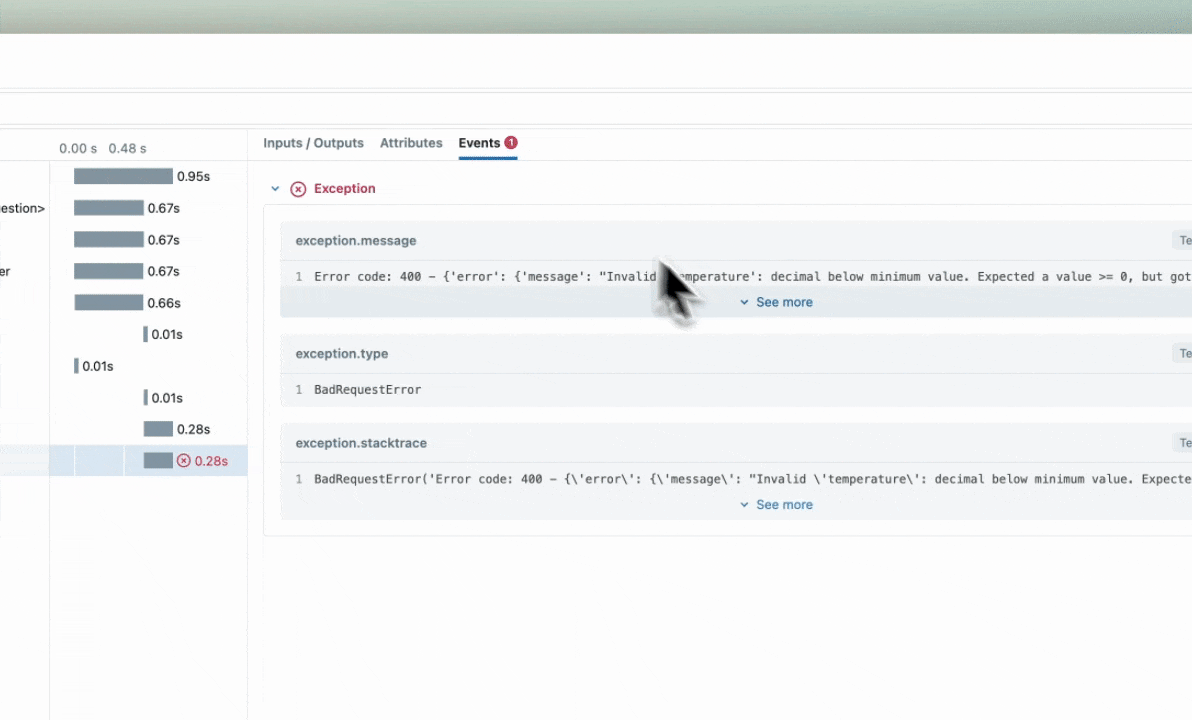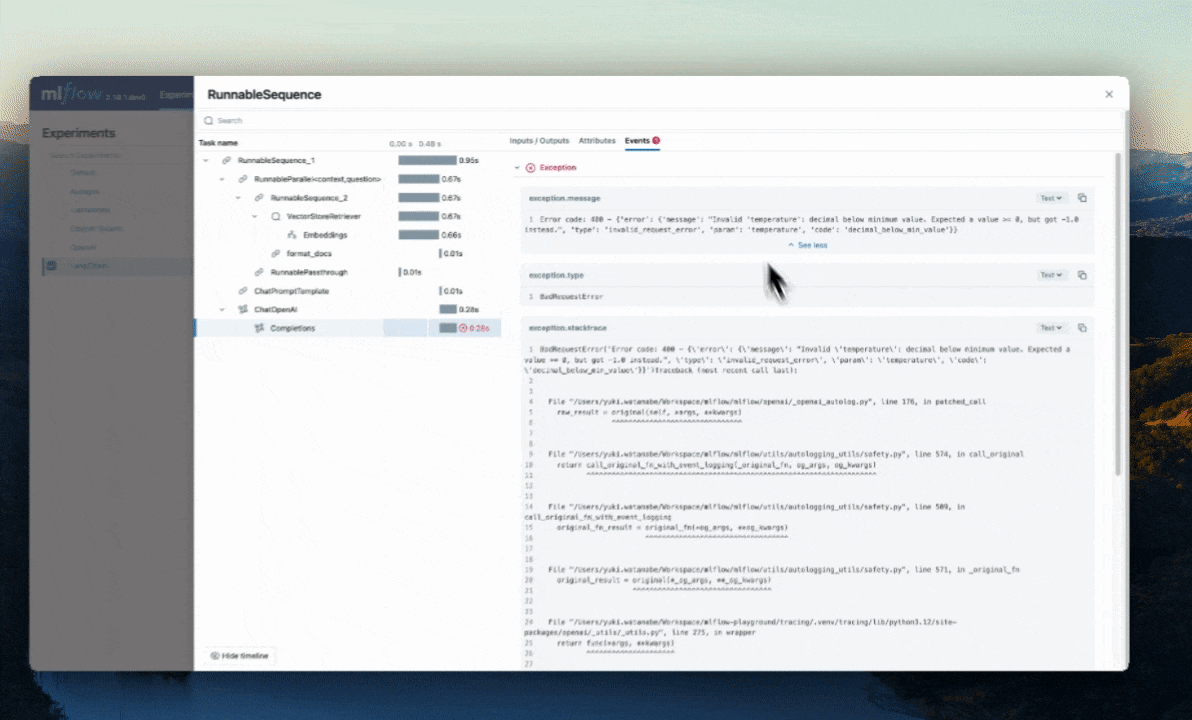
Combining with Auto-Tracing
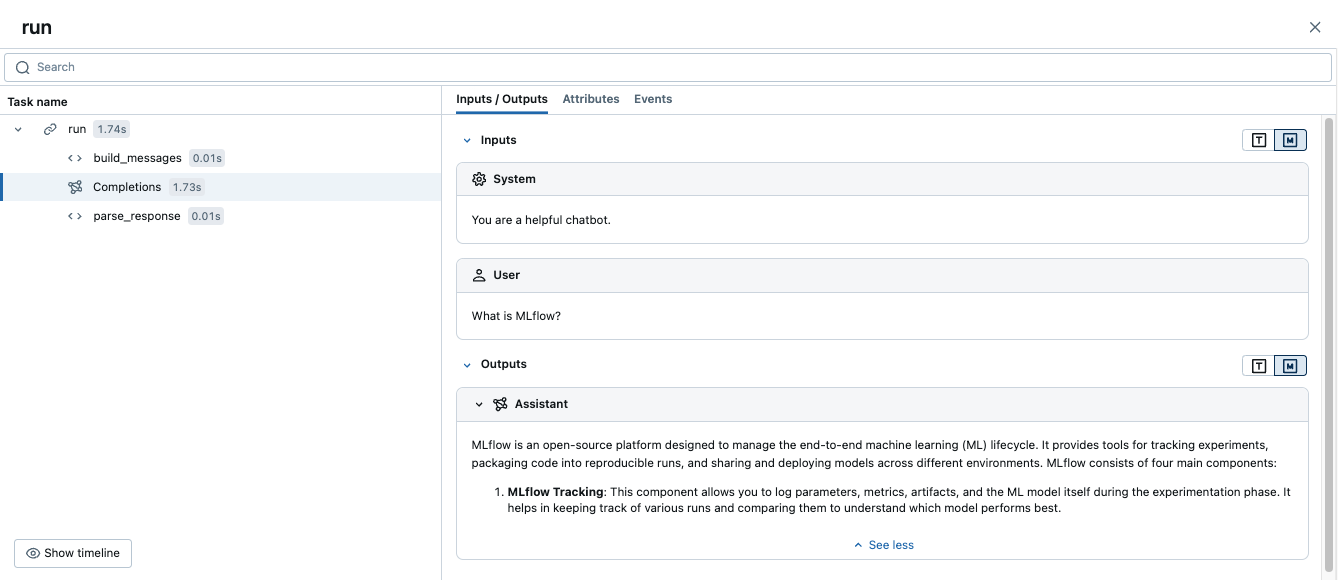
The @mlflow.trace decorator can be used in conjunction with auto tracing. For example, the following code combines OpenAI auto-tracing with manually defined spans in a single cohesive and integrated trace.
import mlflow
import openai
mlflow.openai.autolog()
@mlflow.trace(span_type=SpanType.CHAIN)
def run(question):
messages = build_messages()
# MLflow automatically generates a span for OpenAI invocation
response = openai.OpenAI().chat.completions.create(
model="gpt-4o-mini",
max_tokens=100,
messages=messages,
)
return parse_response(response)
@mlflow.trace
def build_messages(question):
return [
{"role": "system", "content": "You are a helpful chatbot."},
{"role": "user", "content": question},
]
@mlflow.trace
def parse_response(response):
return response.choices[0].message.content
run("What is MLflow?")
Running this code generates the following single trace:
Streaming
The @mlflow.trace decorator can be used to trace functions that return a generator or an iterator, since MLflow 2.20.2.
@mlflow.trace
def stream_data():
for i in range(5):
yield i
The above example will generate a trace with a single span for the stream_data function. By default, MLflow will capture the all elements yielded by the generator as a list in the span's output. In the example above, the output of the span will be [0, 1, 2, 3, 4].
A span for a stream function will start when the returned iterator starts to be consumed, and will end when the iterator is exhausted, or an exception is raised during the iteration.
If you want to aggregate the elements to be a single span output, you can use the output_reducer parameter to specify a custom function to aggregate the elements. The custom function should take a list of yielded elements as inputs.
@mlflow.trace(output_reducer=lambda x: ",".join(x))
def stream_data():
for c in "hello":
yield c
In the example above, the output of the span will be "h,e,l,l,o". The raw chunks can still be found in the Events tab of the span.
The following is an advanced example that uses the output_reducer to consolidate ChatCompletionChunk output from an OpenAI LLM into a single message object.
Of course, we recommend using the auto-tracing for OpenAI for examples like this, which does the same job but with one-liner code. The example below is for demonstration purposes.
import mlflow
import openai
from openai.types.chat import *
from typing import Optional
def aggregate_chunks(outputs: list[ChatCompletionChunk]) -> Optional[ChatCompletion]:
"""Consolidate ChatCompletionChunks to a single ChatCompletion"""
if not outputs:
return None
first_chunk = outputs[0]
delta = first_chunk.choices[0].delta
message = ChatCompletionMessage(
role=delta.role, content=delta.content, tool_calls=delta.tool_calls or []
)
finish_reason = first_chunk.choices[0].finish_reason
for chunk in outputs[1:]:
delta = chunk.choices[0].delta
message.content += delta.content or ""
message.tool_calls += delta.tool_calls or []
finish_reason = finish_reason or chunk.choices[0].finish_reason
base = ChatCompletion(
id=first_chunk.id,
choices=[Choice(index=0, message=message, finish_reason=finish_reason)],
created=first_chunk.created,
model=first_chunk.model,
object="chat.completion",
)
return base
@mlflow.trace(output_reducer=aggregate_chunks)
def predict(messages: list[dict]):
stream = openai.OpenAI().chat.completions.create(
model="gpt-4o-mini",
messages=messages,
stream=True,
)
for chunk in stream:
yield chunk
for chunk in predict([{"role": "user", "content": "Hello"}]):
print(chunk)
In the example above, the generated predict span will have a single chat completion message as the output, which is aggregated by the custom reducer function.
Function Wrapping
Function wrapping provides a flexible way to add tracing to existing functions without modifying their definitions. This is particularly useful when you want to add tracing to third-party functions or functions defined outside of your control. By wrapping an external function with @mlflow.trace, you can capture its inputs, outputs, and execution context.
import math
import mlflow
def invocation(x, y, exp=2):
# Wrap an external function from the math library
traced_pow = mlflow.trace(math.pow)
raised = traced_pow(x, exp)
traced_factorial = mlflow.trace(math.factorial)
factorial = traced_factorial(int(raised))
return response
invocation(4)
Context Manager
In addition to the decorator, MLflow allows for creating a span that can then be accessed within any encapsulated arbitrary code block using the mlflow.start_span() context manager. It can be useful for capturing complex interactions within your code in finer detail than what is possible by capturing the boundaries of a single function.
Similarly to the decorator, the context manager automatically captures parent-child relationship, exceptions, execution time, and works with auto-tracing. However, the name, inputs, and outputs of the span must be provided manually. You can set them via the Span object that is returned from the context manager.
with mlflow.start_span(name="my_span") as span:
span.set_inputs({"x": 1, "y": 2})
z = x + y
span.set_outputs(z)
Below is a slightly more complex example that uses the mlflow.start_span() context manager in conjunction with both the decorator and auto-tracing for OpenAI.
import mlflow
from mlflow.entities import SpanType
@mlflow.trace(span_type=SpanType.CHAIN)
def start_session():
messages = [{"role": "system", "content": "You are a friendly chat bot"}]
while True:
with mlflow.start_span(name="User") as span:
span.set_inputs(messages)
user_input = input(">> ")
span.set_outputs(user_input)
if user_input == "BYE":
break
messages.append({"role": "user", "content": user_input})
response = openai.OpenAI().chat.completions.create(
model="gpt-4o-mini",
max_tokens=100,
messages=messages,
)
answer = response.choices[0].message.content
print(f"🤖: {answer}")
messages.append({"role": "assistant", "content": answer})
mlflow.openai.autolog()
start_session()
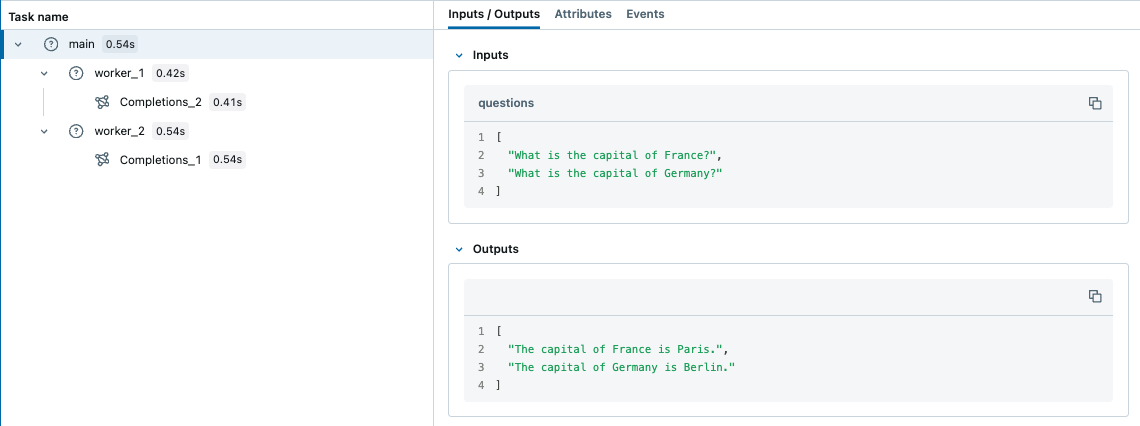
Multi Threading
MLflow Tracing is thread-safe, traces are isolated by default per thread. But you can also create a trace that spans multiple threads with a few additional steps.
MLflow uses Python's built-in ContextVar mechanism to ensure thread safety, which is not propagated across threads by default. Therefore, you need to manually copy the context from the main thread to the worker thread, as shown in the example below.
import contextvars
from concurrent.futures import ThreadPoolExecutor, as_completed
import mlflow
from mlflow.entities import SpanType
import openai
client = openai.OpenAI()
# Enable MLflow Tracing for OpenAI
mlflow.openai.autolog()
@mlflow.trace
def worker(question: str) -> str:
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question},
]
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
temperature=0.1,
max_tokens=100,
)
return response.choices[0].message.content
@mlflow.trace
def main(questions: list[str]) -> list[str]:
results = []
# Almost same as how you would use ThreadPoolExecutor, but two additional steps
# 1. Copy the context in the main thread using copy_context()
# 2. Use ctx.run() to run the worker in the copied context
with ThreadPoolExecutor(max_workers=2) as executor:
futures = []
for question in questions:
ctx = contextvars.copy_context()
futures.append(executor.submit(ctx.run, worker, question))
for future in as_completed(futures):
results.append(future.result())
return results
questions = [
"What is the capital of France?",
"What is the capital of Germany?",
]
main(questions)
In contrast, ContextVar is copied to async tasks by default. Therefore, you don't need to manually copy the context when using asyncio,
which might be an easier way to handle concurrent I/O-bound tasks in Python with MLflow Tracing.
(Advanced) Low-level Client APIs
When the decorator or context manager does not meet your requirements, you can use the low-level client APIs. For example, you might need to start and end a span from different functions. The client API is designed as a thin wrapper over the MLflow REST APIs, giving you more control over the trace lifecycle. For more details, please refer to the MLflow Tracing Client APIs guide.
When using client APIs, please be aware of the following limitations:
- The parent-child relationship is NOT captured automatically. You need to manually pass the ID of the parent span.
- Spans created using the client API do NOT combine with auto-tracing spans.
- Low-level APIs marked as experimental are subject to change based on backend implementation updates.