Tracing AG2🤖
AG2 is an open-source framework for building and orchestrating AI agent interactions.
MLflow Tracing provides automatic tracing capability for AG2, an open-source multi-agent framework. By enabling auto tracing
for AG2 by calling the mlflow.ag2.autolog() function, MLflow will capture nested traces and logged them to the active MLflow Experiment upon agents execution.
Note that since AG2 is built based on AutoGen 0.2, this integration can be used when you use AutoGen 0.2.
import mlflow
mlflow.ag2.autolog()
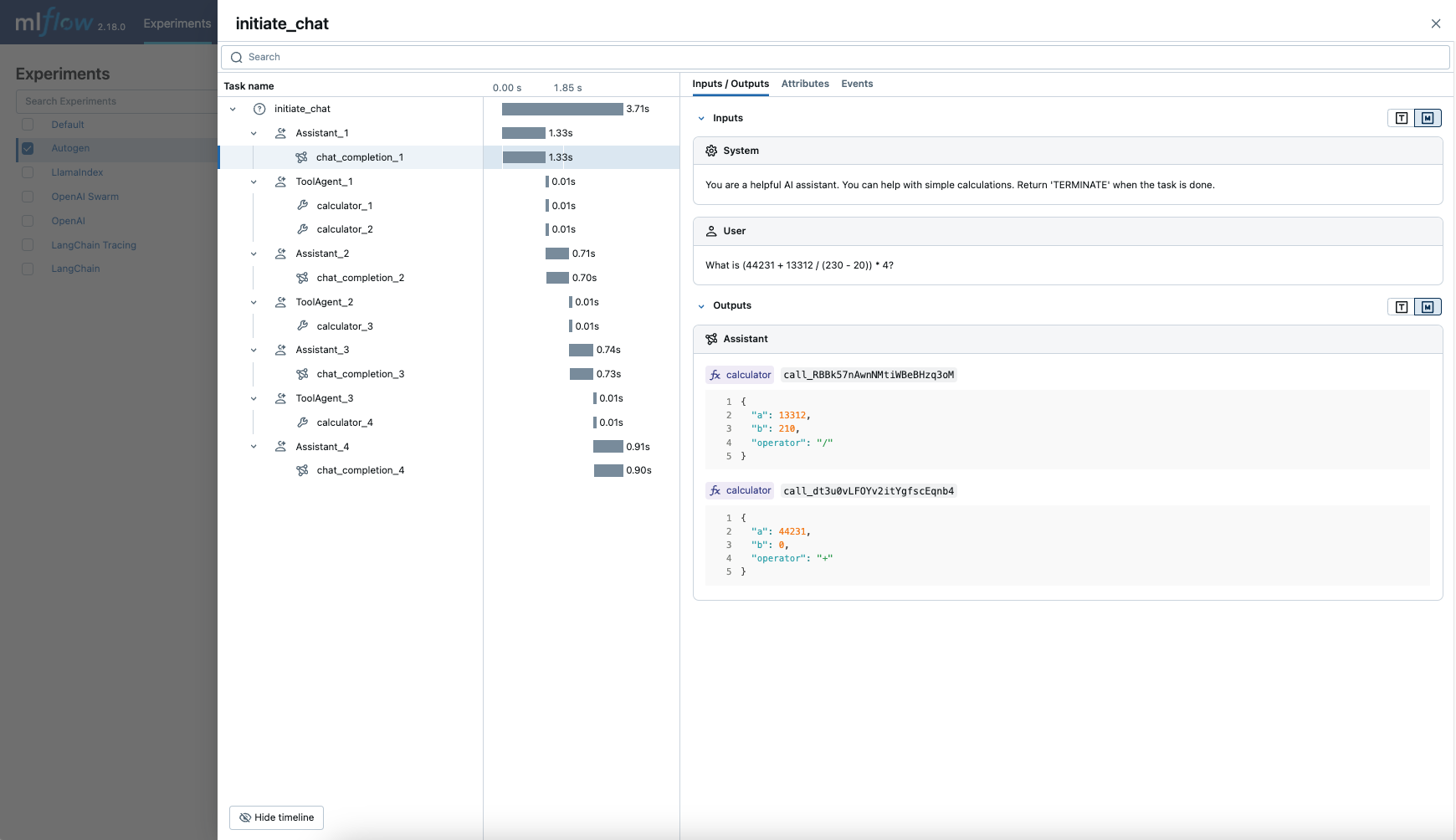
MLflow captures the following information about the multi-agent execution:
- Which agent is called at different turns
- Messages passed between agents
- LLM and tool calls made by each agent, organized per an agent and a turn
- Latencies
- Any exception if raised
Basic Example
import os
from typing import Annotated, Literal
from autogen import ConversableAgent
import mlflow
# Turn on auto tracing for AG2
mlflow.ag2.autolog()
# Optional: Set a tracking URI and an experiment
mlflow.set_tracking_uri("http://localhost:5000")
mlflow.set_experiment("AG2")
# Define a simple multi-agent workflow using AG2
config_list = [
{
"model": "gpt-4o-mini",
# Please set your OpenAI API Key to the OPENAI_API_KEY env var before running this example
"api_key": os.environ.get("OPENAI_API_KEY"),
}
]
Operator = Literal["+", "-", "*", "/"]
def calculator(a: int, b: int, operator: Annotated[Operator, "operator"]) -> int:
if operator == "+":
return a + b
elif operator == "-":
return a - b
elif operator == "*":
return a * b
elif operator == "/":
return int(a / b)
else:
raise ValueError("Invalid operator")
# First define the assistant agent that suggests tool calls.
assistant = ConversableAgent(
name="Assistant",
system_message="You are a helpful AI assistant. "
"You can help with simple calculations. "
"Return 'TERMINATE' when the task is done.",
llm_config={"config_list": config_list},
)
# The user proxy agent is used for interacting with the assistant agent
# and executes tool calls.
user_proxy = ConversableAgent(
name="Tool Agent",
llm_config=False,
is_termination_msg=lambda msg: msg.get("content") is not None
and "TERMINATE" in msg["content"],
human_input_mode="NEVER",
)
# Register the tool signature with the assistant agent.
assistant.register_for_llm(name="calculator", description="A simple calculator")(
calculator
)
user_proxy.register_for_execution(name="calculator")(calculator)
response = user_proxy.initiate_chat(
assistant, message="What is (44231 + 13312 / (230 - 20)) * 4?"
)
Token usage
MLflow >= 3.2.0 supports token usage tracking for AG2. The token usage for each LLM call will be logged in the mlflow.chat.tokenUsage attribute. The total token usage throughout the trace will be
available in the token_usage field of the trace info object.
import json
import mlflow
mlflow.ag2.autolog()
# Register and run the tool signature with the assistant agent which is defined in above section.
assistant.register_for_llm(name="calculator", description="A simple calculator")(
calculator
)
user_proxy.register_for_execution(name="calculator")(calculator)
response = user_proxy.initiate_chat(
assistant, message="What is (44231 + 13312 / (230 - 20)) * 4?"
)
# Get the trace object just created
last_trace_id = mlflow.get_last_active_trace_id()
trace = mlflow.get_trace(trace_id=last_trace_id)
# Print the token usage
total_usage = trace.info.token_usage
print("== Total token usage: ==")
print(f" Input tokens: {total_usage['input_tokens']}")
print(f" Output tokens: {total_usage['output_tokens']}")
print(f" Total tokens: {total_usage['total_tokens']}")
# Print the token usage for each LLM call
print("\n== Detailed usage for each LLM call: ==")
for span in trace.data.spans:
if usage := span.get_attribute("mlflow.chat.tokenUsage"):
print(f"{span.name}:")
print(f" Input tokens: {usage['input_tokens']}")
print(f" Output tokens: {usage['output_tokens']}")
print(f" Total tokens: {usage['total_tokens']}")
== Total token usage: ==
Input tokens: 1569
Output tokens: 229
Total tokens: 1798
== Detailed usage for each LLM call: ==
chat_completion_1:
Input tokens: 110
Output tokens: 61
Total tokens: 171
chat_completion_2:
Input tokens: 191
Output tokens: 61
Total tokens: 252
chat_completion_3:
Input tokens: 269
Output tokens: 24
Total tokens: 293
chat_completion_4:
Input tokens: 302
Output tokens: 23
Total tokens: 325
chat_completion_5:
Input tokens: 333
Output tokens: 22
Total tokens: 355
chat_completion_6:
Input tokens: 364
Output tokens: 38
Total tokens: 402
Disable auto-tracing
Auto tracing for AG2 can be disabled globally by calling mlflow.ag2.autolog(disable=True) or mlflow.autolog(disable=True).