Tracing AutoGen
AutoGen AgentChat is an open-source framework for building conversational single and multi-agent applications.
MLflow Tracing provides automatic tracing capability for AutoGen AgentChat. By enabling auto tracing
for AutoGen by calling the mlflow.autogen.autolog() function, MLflow will capture nested traces and log them to the active MLflow Experiment upon agents execution.
import mlflow
mlflow.autogen.autolog()
Note that mlflow.autogen.autolog() should be called after importing AutoGen classes that are traced.
Subclasses of ChatCompletionClient such as OpenAIChatCompletionClient or AnthropicChatCompletionClient and subclasses of BaseChatAgent such as AssistantAgent or CodeExecutorAgent should be imported before calling mlflow.autogen.autolog().
Also note that this integration is for AutoGen 0.4.9 or above. If you are using AutoGen 0.2, please use the AG2 integration instead.
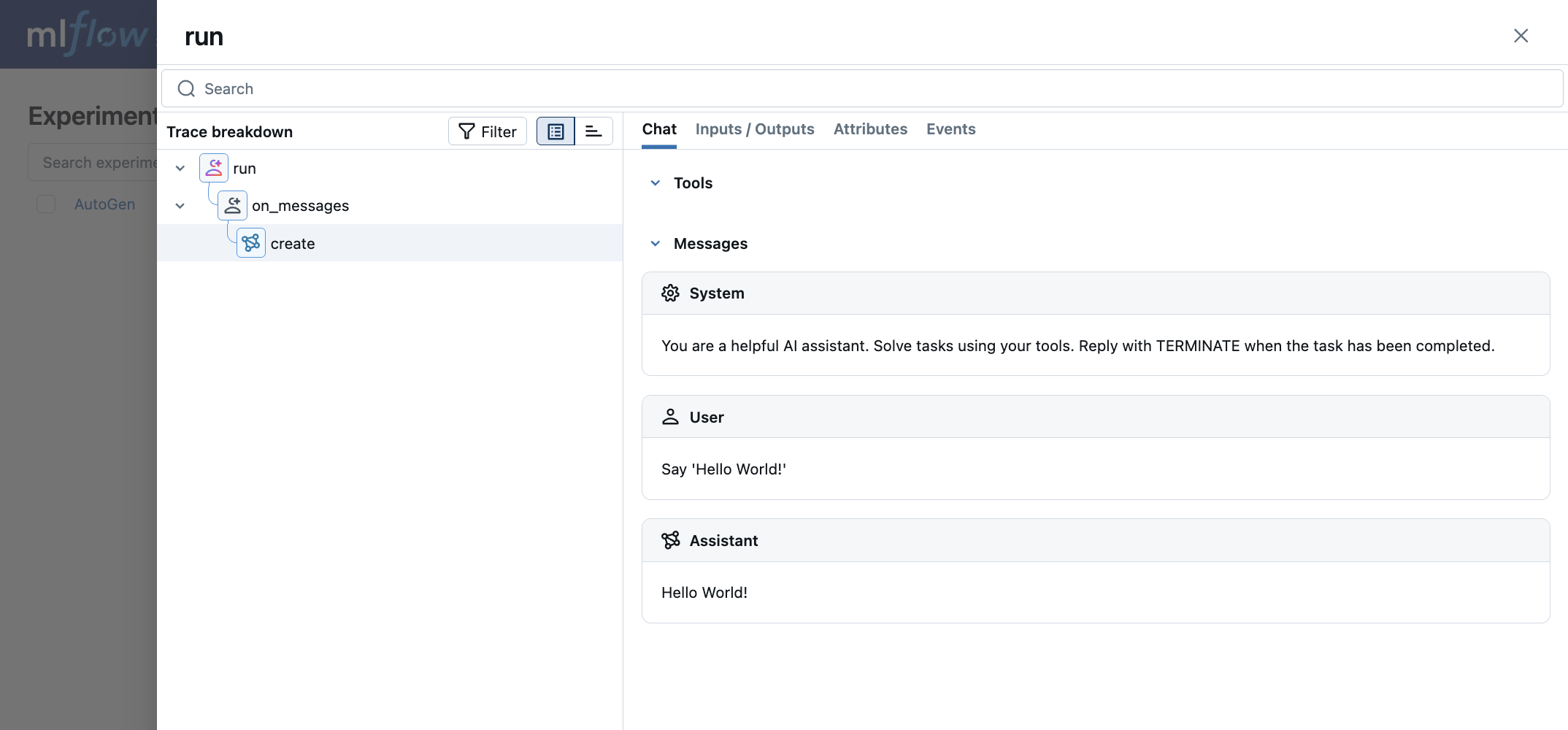
MLflow captures the following information about the AutoGen agents:
- Messages passed to agents including images
- Responses from agents
- LLM and tool calls made by each agent
- Latencies
- Any exception if raised
Supported APIs
MLflow supports automatic tracing for the following AutoGen APIs.
It does not support tracing for asynchronous generators. Asynchronous streaming APIs such as run_stream or on_messages_stream are not traced.
ChatCompletionClient.createBaseChatAgent.runBaseChatAgent.on_messages
Basic Example
import os
# Imports of autogen classes should happen before calling autolog.
from autogen_agentchat.agents import AssistantAgent
from autogen_ext.models.openai import OpenAIChatCompletionClient
import mlflow
# Turn on auto tracing for AutoGen
mlflow.autogen.autolog()
# Optional: Set a tracking URI and an experiment
mlflow.set_tracking_uri("http://localhost:5000")
mlflow.set_experiment("AutoGen")
model_client = OpenAIChatCompletionClient(
model="gpt-4.1-nano",
# api_key="YOUR_API_KEY",
)
agent = AssistantAgent(
name="assistant",
model_client=model_client,
system_message="You are a helpful assistant.",
)
result = await agent.run(task="Say 'Hello World!'")
print(result)
Tool Agent
import os
# Imports of autogen classes should happen before calling autolog.
from autogen_agentchat.agents import AssistantAgent
from autogen_ext.models.openai import OpenAIChatCompletionClient
import mlflow
# Turn on auto tracing for AutoGen
mlflow.autogen.autolog()
# Optional: Set a tracking URI and an experiment
mlflow.set_tracking_uri("http://localhost:5000")
mlflow.set_experiment("AutoGen")
model_client = OpenAIChatCompletionClient(
model="gpt-4.1-nano",
# api_key="YOUR_API_KEY",
)
def add(a: int, b: int) -> int:
"""add two numbers"""
return a + b
agent = AssistantAgent(
name="assistant",
model_client=model_client,
system_message="You are a helpful assistant.",
tools=[add],
)
await agent.run(task="1+1")
Token usage
MLflow >= 3.2.0 supports token usage tracking for AutoGen. The token usage for each LLM call will be logged in the mlflow.chat.tokenUsage attribute. The total token usage throughout the trace will be
available in the token_usage field of the trace info object.
import json
import mlflow
mlflow.autogen.autolog()
# Run the tool calling agent defined in the previous section
await agent.run(task="1+1")
# Get the trace object just created
last_trace_id = mlflow.get_last_active_trace_id()
trace = mlflow.get_trace(trace_id=last_trace_id)
# Print the token usage
total_usage = trace.info.token_usage
print("== Total token usage: ==")
print(f" Input tokens: {total_usage['input_tokens']}")
print(f" Output tokens: {total_usage['output_tokens']}")
print(f" Total tokens: {total_usage['total_tokens']}")
# Print the token usage for each LLM call
print("\n== Detailed usage for each LLM call: ==")
for span in trace.data.spans:
if usage := span.get_attribute("mlflow.chat.tokenUsage"):
print(f"{span.name}:")
print(f" Input tokens: {usage['input_tokens']}")
print(f" Output tokens: {usage['output_tokens']}")
print(f" Total tokens: {usage['total_tokens']}")
== Total token usage: ==
Input tokens: 65
Output tokens: 17
Total tokens: 82
== Detailed usage for each LLM call: ==
create:
Input tokens: 65
Output tokens: 17
Total tokens: 82
Supported APIs
MLflow supports automatic token usage tracking for the following AutoGen APIs.
It does not support token usage tracking for asynchronous generators. Asynchronous streaming APIs such as run_stream or on_messages_stream are not tracked.
ChatCompletionClient.createBaseChatAgent.runBaseChatAgent.on_messages
Disable auto-tracing
Auto tracing for AutoGen can be disabled globally by calling mlflow.autogen.autolog(disable=True) or mlflow.autolog(disable=True).