Tracing Ollama
Ollama is an open-source platform that enables users to run large language models (LLMs) locally on their devices, such as Llama 3.2, Gemma 2, Mistral, Code Llama, and more.
Since the local LLM endpoint served by Ollama is compatible with the OpenAI API, you can query it via OpenAI SDK and enable tracing for Ollama with mlflow.openai.autolog(). Any LLM interactions via Ollama will be recorded to the active MLflow Experiment.
import mlflow
mlflow.openai.autolog()
Example Usage
- Run the Ollama server with the desired LLM model.
ollama run llama3.2:1b
- Enable auto-tracing for OpenAI SDK.
import mlflow
# Enable auto-tracing for OpenAI
mlflow.openai.autolog()
# Optional: Set a tracking URI and an experiment
mlflow.set_tracking_uri("http://localhost:5000")
mlflow.set_experiment("Ollama")
- Query the LLM and see the traces in the MLflow UI.
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1", # The local Ollama REST endpoint
api_key="dummy", # Required to instantiate OpenAI client, it can be a random string
)
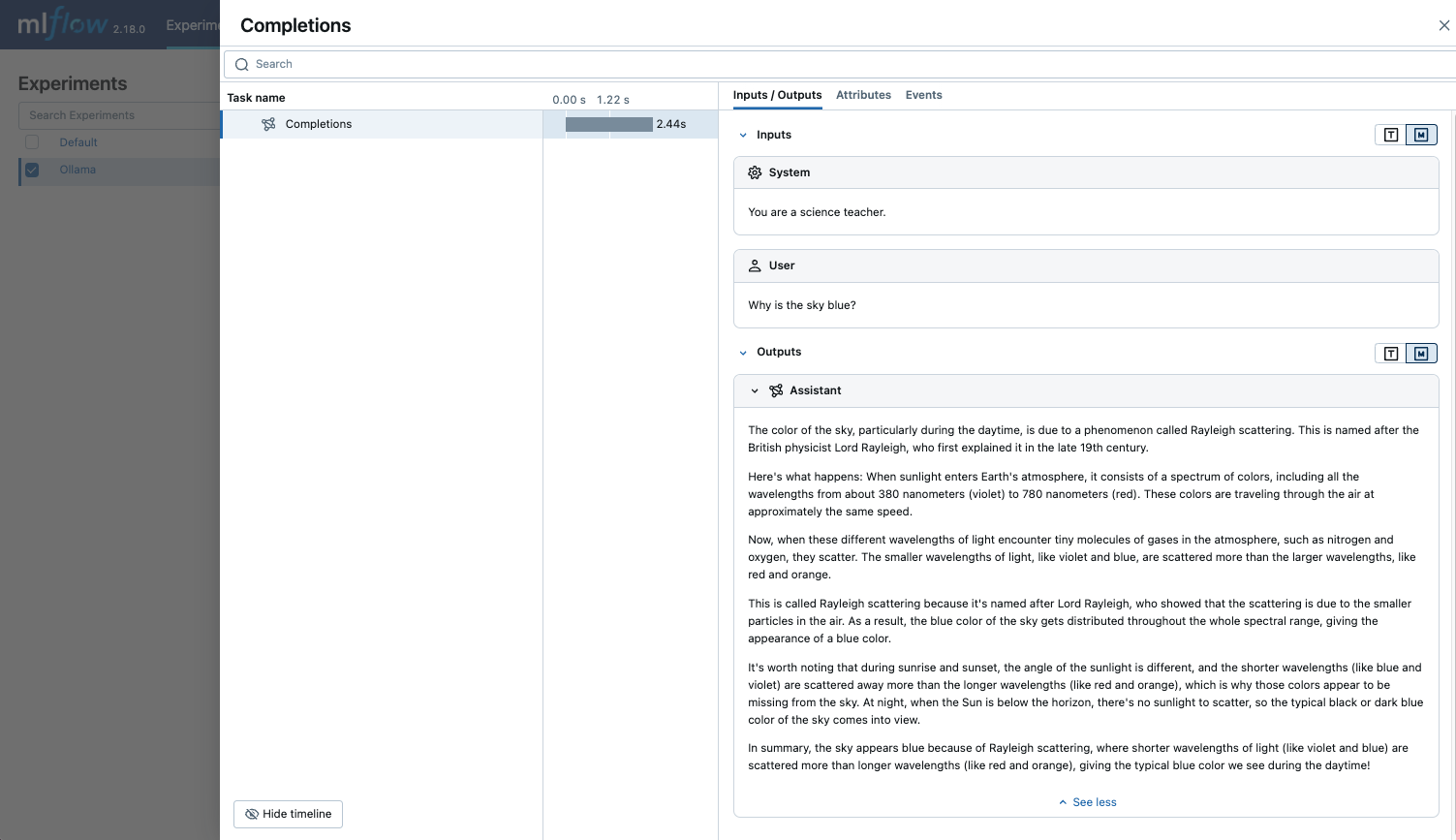
response = client.chat.completions.create(
model="llama3.2:1b",
messages=[
{"role": "system", "content": "You are a science teacher."},
{"role": "user", "content": "Why is the sky blue?"},
],
)
Token usage
MLflow >= 3.2.0 supports token usage tracking for local LLM endpoint served through OpenAI SDK. The token usage for each LLM call will be logged in the mlflow.chat.tokenUsage attribute. The total token usage throughout the trace will be
available in the token_usage field of the trace info object.
import json
import mlflow
mlflow.openai.autolog()
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:11434/v1", # The local Ollama REST endpoint
api_key="dummy", # Required to instantiate OpenAI client, it can be a random string
)
response = client.chat.completions.create(
model="llama3.2:1b",
messages=[
{"role": "system", "content": "You are a science teacher."},
{"role": "user", "content": "Why is the sky blue?"},
],
)
# Get the trace object just created
last_trace_id = mlflow.get_last_active_trace_id()
trace = mlflow.get_trace(trace_id=last_trace_id)
# Print the token usage
total_usage = trace.info.token_usage
print("== Total token usage: ==")
print(f" Input tokens: {total_usage['input_tokens']}")
print(f" Output tokens: {total_usage['output_tokens']}")
print(f" Total tokens: {total_usage['total_tokens']}")
# Print the token usage for each LLM call
print("\n== Detailed usage for each LLM call: ==")
for span in trace.data.spans:
if usage := span.get_attribute("mlflow.chat.tokenUsage"):
print(f"{span.name}:")
print(f" Input tokens: {usage['input_tokens']}")
print(f" Output tokens: {usage['output_tokens']}")
print(f" Total tokens: {usage['total_tokens']}")
== Total token usage: ==
Input tokens: 23
Output tokens: 194
Total tokens: 217
== Detailed usage for each LLM call: ==
Completions:
Input tokens: 23
Output tokens: 194
Total tokens: 217
Disable auto-tracing
Auto tracing for Ollama can be disabled globally by calling mlflow.openai.autolog(disable=True) or mlflow.autolog(disable=True).