MLflow Overview
Stepping into the world of Machine Learning (ML) is an exciting journey, but it often comes with complexities that can hinder innovation and experimentation.
MLflow is a solution to many of these issues in this dynamic landscape, offering tools and simplifying processes to streamline the ML lifecycle and foster collaboration among ML practitioners.
Whether you’re an individual researcher, a member of a large team, or somewhere in between, MLflow provides a unified platform to navigate the intricate maze of model development, deployment, and management. MLflow aims to enable innovation in ML solution development by streamlining otherwise cumbersome logging, organization, and lineage concerns that are unique to model development. This focus allows you to ensure that your ML projects are robust, transparent, and ready for real-world challenges.
Read on to discover the core components of MLflow and understand the unique advantages it brings to the complex workflows associated with model development and management.
Core Components of MLflow
MLflow, at its core, provides a suite of tools aimed at simplifying the ML workflow. It is tailored to assist ML practitioners throughout the various stages of ML development and deployment. Despite its expansive offerings, MLflow’s functionalities are rooted in several foundational components:
Tracking: MLflow Tracking provides both an API and UI dedicated to the logging of parameters, code versions, metrics, and artifacts during the ML process. This centralized repository captures details such as parameters, metrics, artifacts, data, and environment configurations, giving teams insight into their models’ evolution over time. Whether working in standalone scripts, notebooks, or other environments, Tracking facilitates the logging of results either to local files or a server, making it easier to compare multiple runs across different users.
Model Registry: A systematic approach to model management, the Model Registry assists in handling different versions of models, discerning their current state, and ensuring smooth productionization. It offers a centralized model store, APIs, and UI to collaboratively manage an MLflow Model’s full lifecycle, including model lineage, versioning, aliasing, tagging, and annotations.
MLflow Deployments for LLMs: This server, equipped with a set of standardized APIs, streamlines access to both SaaS and OSS LLM models. It serves as a unified interface, bolstering security through authenticated access, and offers a common set of APIs for prominent LLMs.
Evaluate: Designed for in-depth model analysis, this set of tools facilitates objective model comparison, be it traditional ML algorithms or cutting-edge LLMs.
Prompt Engineering UI: A dedicated environment for prompt engineering, this UI-centric component provides a space for prompt experimentation, refinement, evaluation, testing, and deployment.
Recipes: Serving as a guide for structuring ML projects, Recipes, while offering recommendations, are focused on ensuring functional end results optimized for real-world deployment scenarios.
Projects: MLflow Projects standardize the packaging of ML code, workflows, and artifacts, akin to an executable. Each project, be it a directory with code or a Git repository, employs a descriptor or convention to define its dependencies and execution method.
By integrating these core components, MLflow offers an end-to-end platform, ensuring efficiency, consistency, and traceability throughout the ML lifecycle.
Why Use MLflow?
The machine learning (ML) process is intricate, comprising various stages, from data preprocessing to model deployment and monitoring. Ensuring productivity and efficiency throughout this lifecycle poses several challenges:
Experiment Management: It’s tough to keep track of the myriad experiments, especially when working with files or interactive notebooks. Determining which combination of data, code, and parameters led to a particular result can become a daunting task.
Reproducibility: Ensuring consistent results across runs is not trivial. Beyond just tracking code versions and parameters, capturing the entire environment, including library dependencies, is critical. This becomes even more challenging when collaborating with other data scientists or when scaling the code to different platforms.
Deployment Consistency: With the plethora of ML libraries available, there’s often no standardized way to package and deploy models. Custom solutions can lead to inconsistencies, and the crucial link between a model and the code and parameters that produced it might be lost.
Model Management: As data science teams produce numerous models, managing, testing, and continuously deploying these models becomes a significant hurdle. Without a centralized platform, managing model lifecycles becomes unwieldy.
Library Agnosticism: While individual ML libraries might offer solutions to some of the challenges, achieving the best results often involves experimenting across multiple libraries. A platform that offers compatibility with various libraries while ensuring models are usable as reproducible “black boxes” is essential.
MLflow addresses these challenges by offering a unified platform tailored for the entire ML lifecycle. Its benefits include:
Traceability: With tools like the Tracking Server, every experiment is logged, ensuring that teams can trace back and understand the evolution of models.
Consistency: Be it accessing models through the MLflow Deployments for LLMs or structuring projects with MLflow Recipes, MLflow promotes a consistent approach, reducing both the learning curve and potential errors.
Flexibility: MLflow’s library-agnostic design ensures compatibility with a wide range of machine learning libraries. It offers comprehensive support across different programming languages, backed by a robust REST API, CLI, and APIs for Python API, R API, and Java API.
By simplifying the complex landscape of ML workflows, MLflow empowers data scientists and developers to focus on building and refining models, ensuring a streamlined path from experimentation to production.
Who Uses MLflow?
Throughout the lifecycle of a particular project, there are components within MLflow that are designed to cater to different needs.
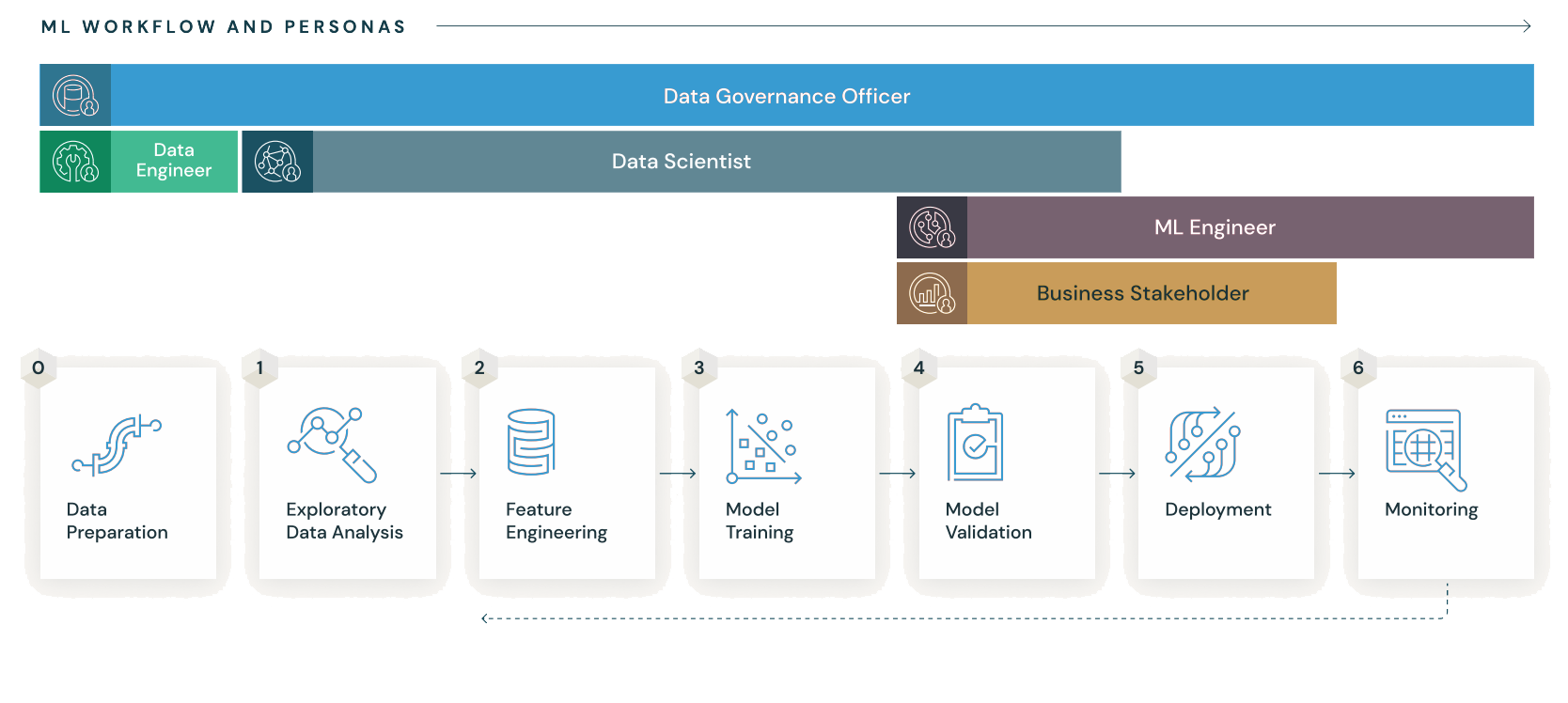
MLflow’s versatility enhances workflows across various roles, from data scientists to prompt engineers, extending its impact beyond just the confines of a Data Science team.
Data Scientists leverage MLflow for:
Experiment tracking and hypothesis testing persistence.
Code structuring for better reproducibility.
Model packaging and dependency management.
Evaluating hyperparameter tuning selection boundaries.
Comparing the results of model retraining over time.
Reviewing and selecting optimal models for deployment.
MLOps Professionals utilize MLflow to:
Manage the lifecycles of trained models, both pre and post deployment.
Deploy models securely to production environments.
Audit and review candidate models prior to deployment.
Manage deployment dependencies.
Data Science Managers interact with MLflow by:
Reviewing the outcomes of experimentation and modeling activities.
Collaborating with teams to ensure that modeling objectives align with business goals.
Prompt Engineering Users use MLflow for:
Evaluating and experimenting with large language models.
Crafting custom prompts and persisting their candidate creations.
Deciding on the best base model suitable for their specific project requirements.
Use Cases of MLflow
MLflow is versatile, catering to diverse machine learning scenarios. Here are some typical use cases:
Experiment Tracking: A data science team leverages MLflow Tracking to log parameters and metrics for experiments within a particular domain. Using the MLflow UI, they can compare results and fine-tune their solution approach. The outcomes of these experiments are preserved as MLflow models.
Model Selection and Deployment: MLOps engineers employ the MLflow UI to assess and pick the top-performing models. The chosen model is registered in the MLflow Registry, allowing for monitoring its real-world performance.
Model Performance Monitoring: Post deployment, MLOps engineers utilize the MLflow Registry to gauge the model’s efficacy, juxtaposing it against other models in a live environment.
Collaborative Projects: Data scientists embarking on new ventures organize their work as an MLflow Project. This structure facilitates easy sharing and parameter modifications, promoting collaboration.
Scalability in MLflow
MLflow is architected to seamlessly integrate with diverse data environments, from small datasets to Big Data applications. It’s built with the understanding that quality machine learning outcomes often hinge on robust data sources, and as such, scales adeptly to accommodate varying data needs.
Here’s how MLflow addresses scalability across different dimensions:
Distributed Execution: MLflow runs can operate on distributed clusters. For instance, integration with Apache Spark allows for distributed processing. Furthermore, runs can be initiated on the distributed infrastructure of your preference, with results relayed to a centralized Tracking Server for analysis. Notably, MLflow offers an integrated API to initiate runs on Databricks.
Parallel Runs: For use cases like hyperparameter tuning, MLflow can orchestrate multiple runs simultaneously, each with distinct parameters.
Interoperability with Distributed Storage: MLflow Projects can interface with distributed storage solutions, including Azure ADLS, Azure Blob Storage, AWS S3, Cloudflare R2 and DBFS. Whether it’s automatically fetching files to a local environment or interfacing with a distributed storage URI directly, MLflow ensures that projects can handle extensive datasets – even scenarios like processing a 100 TB file.
Centralized Model Management with Model Registry: Large-scale organizations can benefit from the MLflow Model Registry, a unified platform tailored for collaborative model lifecycle management. In environments where multiple data science teams might be concurrently developing numerous models, the Model Registry proves invaluable. It streamlines model discovery, tracks experiments, manages versions, and facilitates understanding a model’s intent across different teams.
By addressing these scalability dimensions, MLflow ensures that users can capitalize on its capabilities regardless of their data environment’s size or complexity.