Deployment
Important
This page describes the toolset for deploying your in-house MLflow Model. For information on the LLM Deployment Server (formerly known as AI Gateway), please refer to MLflow Deployment Server.
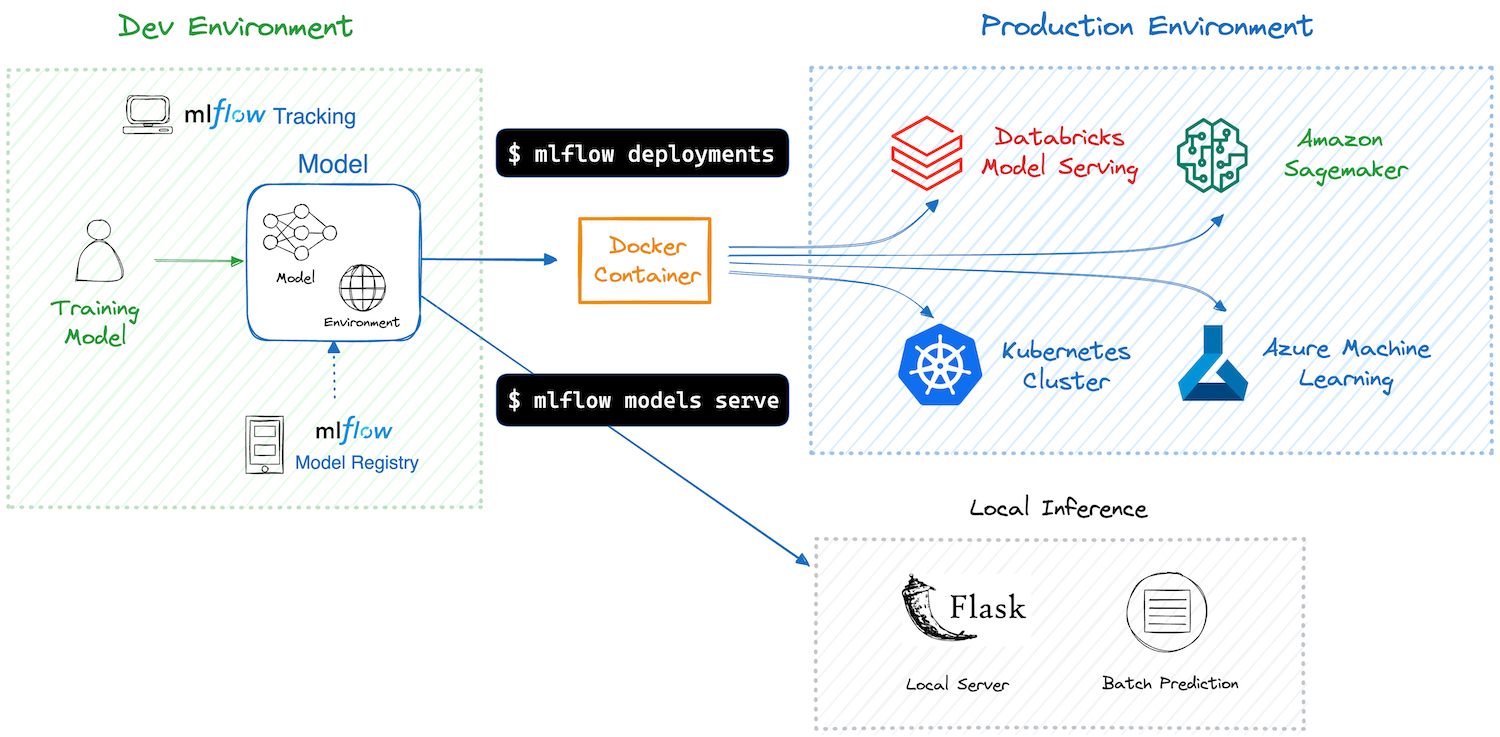
After training your machine learning model and ensuring its performance, the next step is deploying it to a production environment. This process can be complex, but MLflow simplifies it by offering an easy toolset for deploying your ML models to various targets, including local environments, cloud services, and Kubernetes clusters.
By using MLflow deployment toolset, you can enjoy the following benefits:
Effortless Deployment: MLflow provides a simple interface for deploying models to various targets, eliminating the need to write boilerplate code.
Dependency and Environment Management: MLflow ensures that the deployment environment mirrors the training environment, capturing all dependencies. This guarantees that models run consistently, regardless of where they’re deployed.
Packaging Models and Code: With MLflow, not just the model, but any supplementary code and configurations are packaged along with the deployment container. This ensures that the model can be executed seamlessly without any missing components.
Avoid Vendor Lock-in: MLflow provides a standard format for packaging models and unified APIs for deployment. You can easily switch between deployment targets without having to rewrite your code.
Concepts
MLflow Model
MLflow Model is a standard format that packages a machine learning model with its metadata, such as dependencies and inference schema.
You typically create a model as a result of training execution using the MLflow Tracking APIs, for instance, mlflow.pyfunc.log_model().
Alternatively, models can be registered and retrieved via the MLflow Model Registry.
To use MLflow deployment, you must first create a model.
Container
Container plays a critical role for simplifying and standardizing the model deployment process. MLflow uses Docker containers to package models with their dependencies, enabling deployment to various destinations without environment compatibility issues. See Building a Docker Image for MLflow Model for more details on how to deploy your model as a container. If you’re new to Docker, you can start learning at “What is a Container”.
How it works
An MLflow Model already packages your model and its dependencies, hence MLflow can create either a virtual environment (for local deployment) or a Docker container image containing everything needed to run your model. Subsequently, MLflow launches an inference server with REST endpoints using frameworks like Flask, preparing it for deployment to various destinations to handle inference requests. Detailed information about the server and endpoints is available in Inference Server Specification.
MLflow provides CLI commands and Python APIs to facilitate the deployment process. The required commands differ based on the deployment target, so please continue reading to the next section for more details about your specific target.
Supported Deployment Targets
MLflow offers support for a variety of deployment targets. For detailed information and tutorials on each, please follow the respective links below.
API References
Command Line Interface
Deployment-related commands are primarily categorized under two modules:
mlflow models - typically used for local deployment.
mlflow deployments - typically used for deploying to custom targets.
Note that these categories are not strictly separated and may overlap. Furthermore, certain targets require custom modules or plugins, for example, mlflow sagemaker is used for Amazon SageMaker deployments, and the azureml-mlflow library is required for Azure ML.
Therefore, it is advisable to consult the specific documentation for your chosen target to identify the appropriate commands.
FAQ
If you encounter any dependency issues during model deployment, please refer to Model Dependencies FAQ for guidance on how to troubleshoot and validate fixes.