MLflow Langchain Autologging
MLflow LangChain flavor supports autologging, a powerful feature that allows you to log crucial details about the LangChain model and execution without the need for explicit logging statements. MLflow LangChain autologging covers various aspects of the model, including traces, models, signatures and more.
Attention
MLflow’s LangChain Autologging feature has been overhauled in the MLflow 2.14.0 release. If you are using the earlier version of MLflow, please refer to the legacy documentation here for applicable autologging documentation.
Note
MLflow LangChain Autologging is verified to be compatible with LangChain versions between 0.1.0 and 0.2.3. Outside of this range, the feature may not work as expected. To install the compatible version of LangChain, please run the following command:
pip install mlflow[langchain] --upgrade
Table of Contents
Quickstart
To enable autologging for LangChain models, call mlflow.langchain.autolog() at the beginning of your script or notebook. This will automatically log the traces by default as well as other artifacts such as models, input examples, and model signatures if you explicitly enable them. For more information about the configuration, please refer to the Configure Autologging section.
import mlflow
mlflow.langchain.autolog()
# Enable other optional logging
# mlflow.langchain.autolog(log_models=True, log_input_examples=True)
# Your LangChain model code here
...
Once you have invoked the chain, you can view the logged traces and artifacts in the MLflow UI.
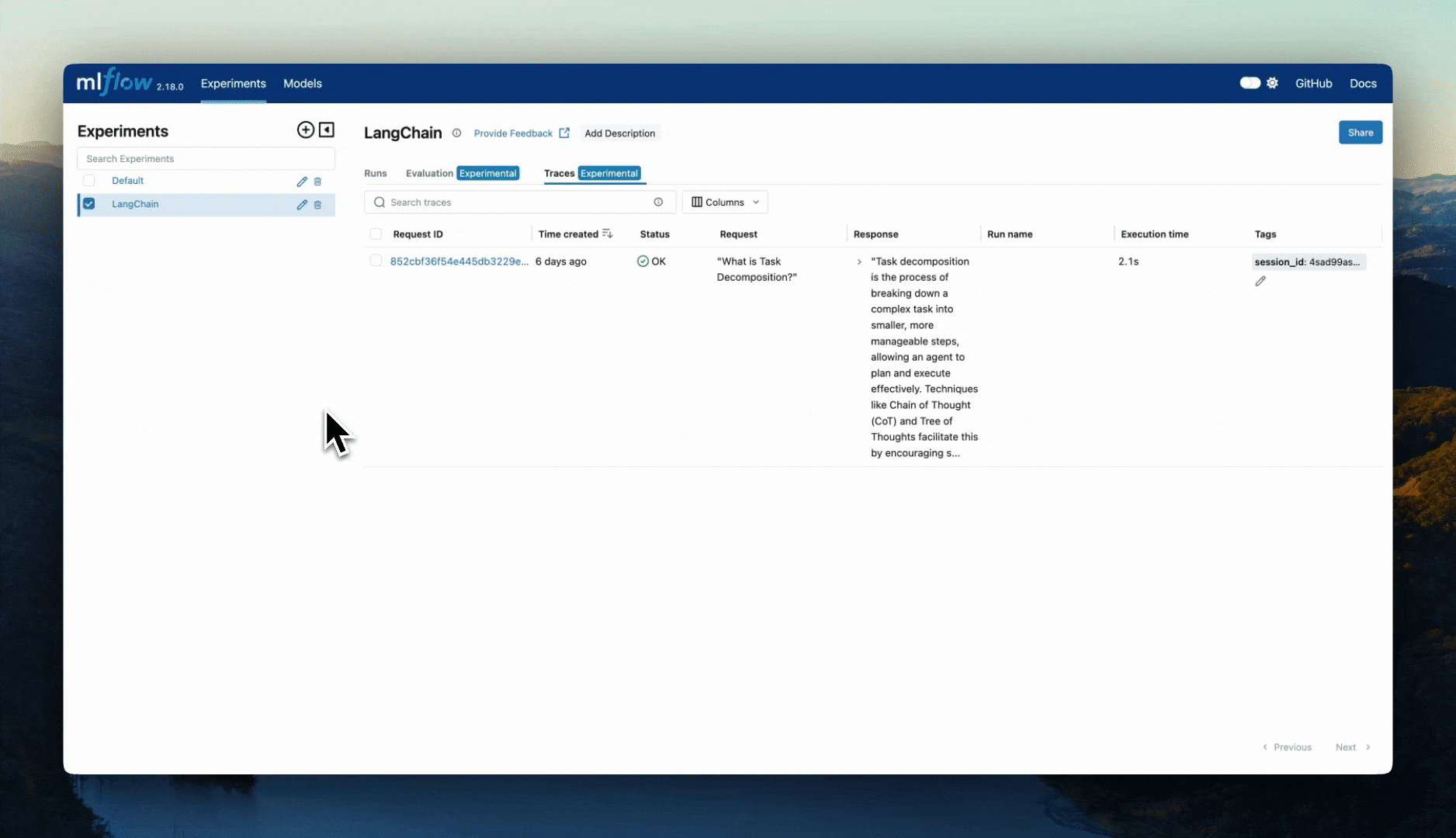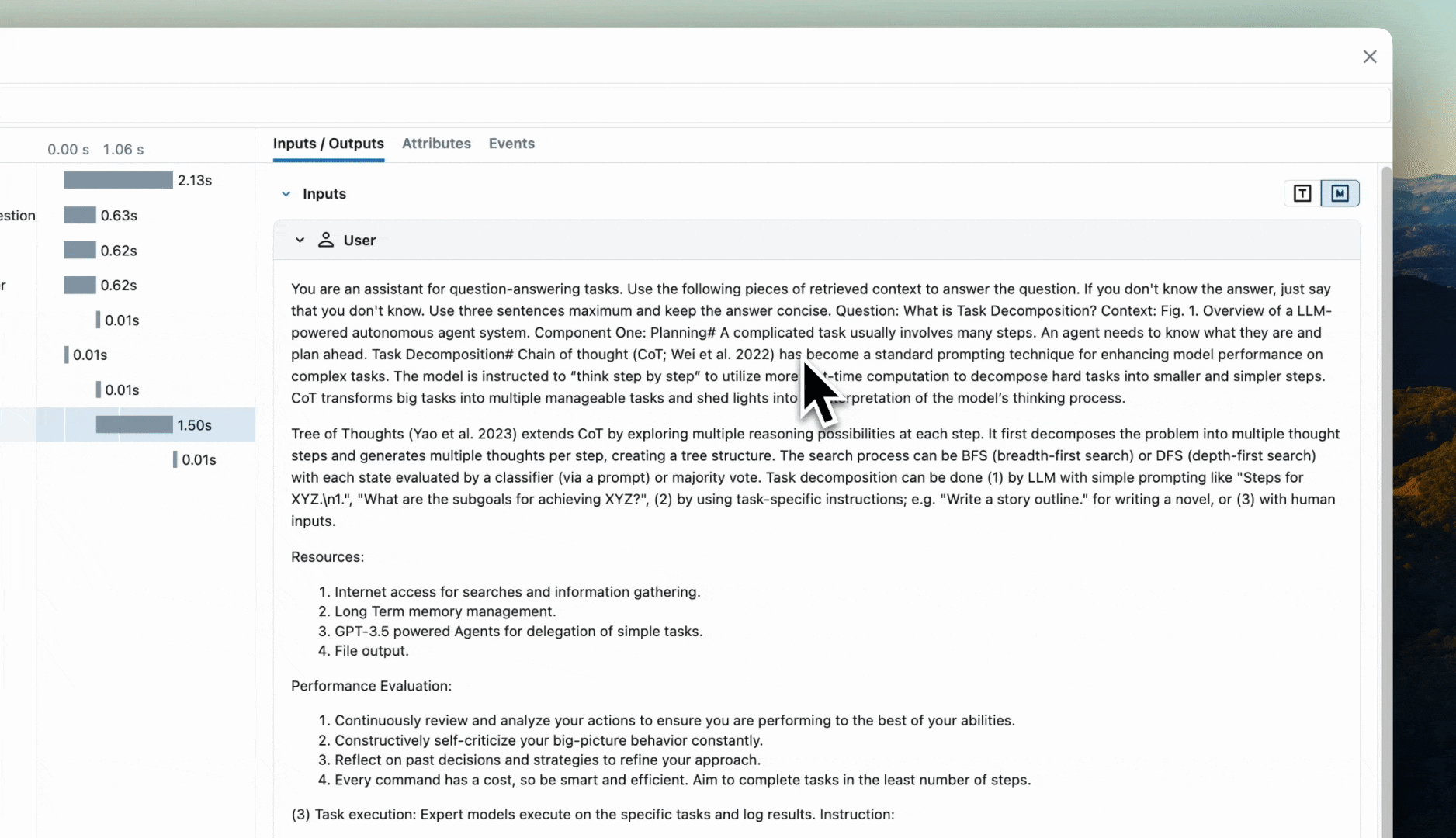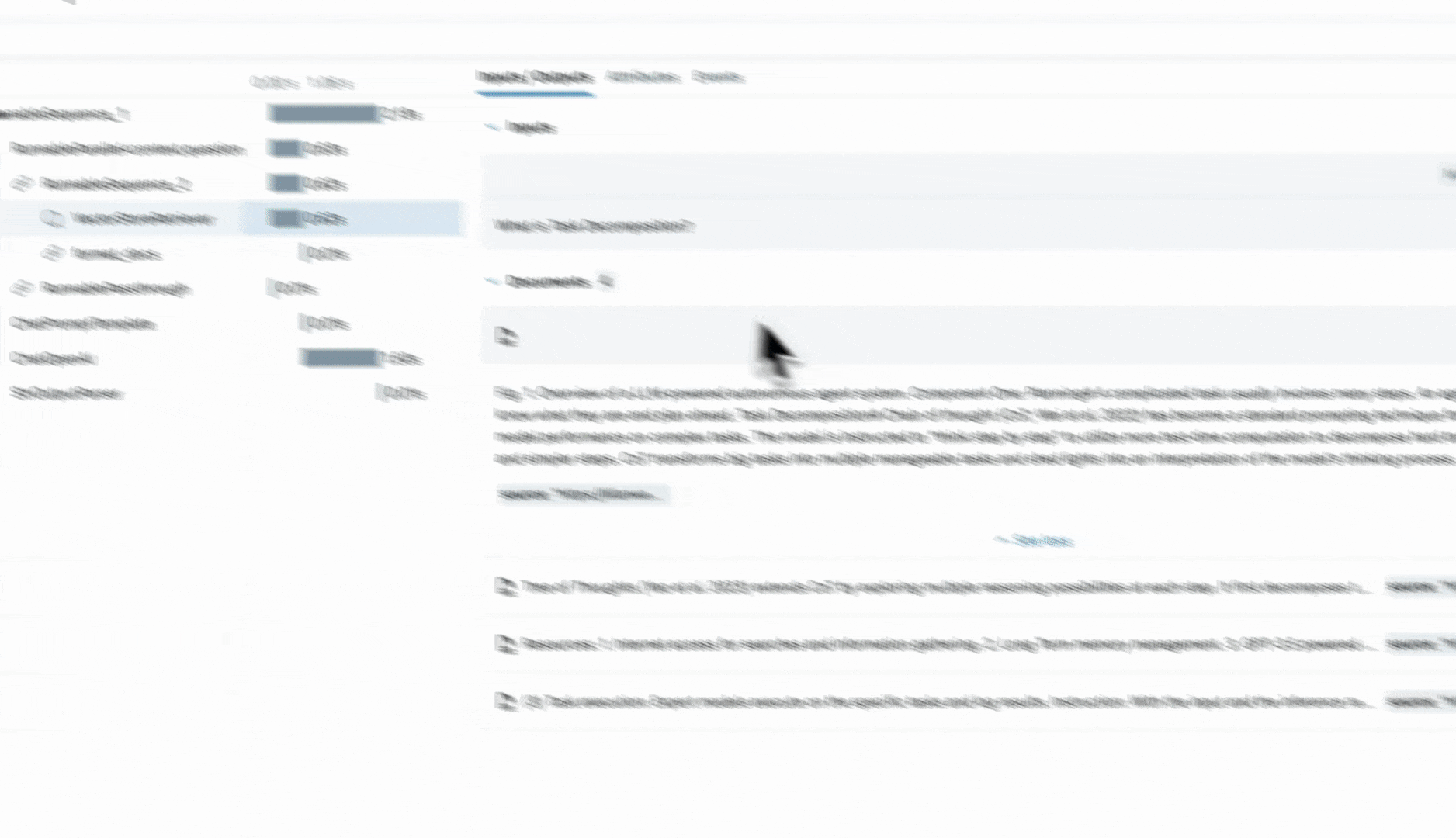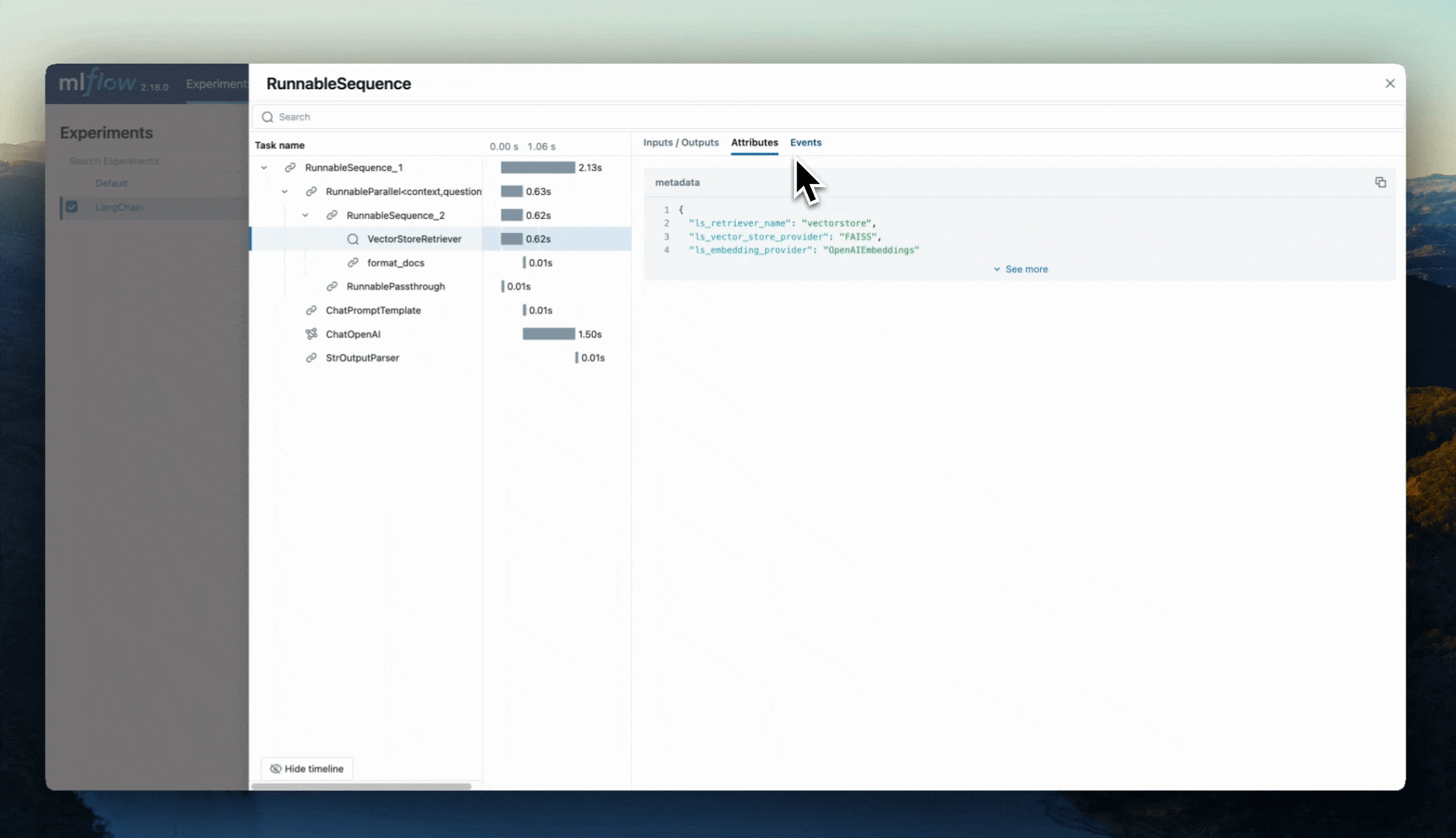
Configure Autologging
MLflow LangChain autologging can log various information about the model and its inference. By default, only trace logging is enabled, but you can enable autologging of other information by setting the corresponding parameters when calling mlflow.langchain.autolog(). For other configurations, please refer to the API documentation.
Target |
Default |
Parameter |
Description |
|---|---|---|---|
Traces |
|
|
Whether to generate and log traces for the model. See MLflow Tracing for more details about tracing feature. |
Model Artifacts |
|
|
If set to |
Model Signatures |
|
|
If set to |
Input Example |
|
|
If set to |
For example, to disable logging of traces, and instead enable model logging, run the following code:
import mlflow
mlflow.langchain.autolog(
log_traces=False,
log_models=True,
)
Note
MLflow does not support automatic model logging for chains that contain retrievers. Saving retrievers requires additional loader_fn and persist_dir information for loading the model. If you want to log the model with retrievers, please log the model manually as shown in the retriever_chain example.
Example Code of LangChain Autologging
import os
from operator import itemgetter
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableLambda
import mlflow
# Uncomment the following to use the full abilities of langchain autologgin
# %pip install `langchain_community>=0.0.16`
# These two libraries enable autologging to log text analysis related artifacts
# %pip install textstat spacy
assert "OPENAI_API_KEY" in os.environ, "Please set the OPENAI_API_KEY environment variable."
# Enable mlflow langchain autologging
# Note: We only support auto-logging models that do not contain retrievers
mlflow.langchain.autolog(
log_input_examples=True,
log_model_signatures=True,
log_models=True,
registered_model_name="lc_model",
)
prompt_with_history_str = """
Here is a history between you and a human: {chat_history}
Now, please answer this question: {question}
"""
prompt_with_history = PromptTemplate(
input_variables=["chat_history", "question"], template=prompt_with_history_str
)
def extract_question(input):
return input[-1]["content"]
def extract_history(input):
return input[:-1]
llm = OpenAI(temperature=0.9)
# Build a chain with LCEL
chain_with_history = (
{
"question": itemgetter("messages") | RunnableLambda(extract_question),
"chat_history": itemgetter("messages") | RunnableLambda(extract_history),
}
| prompt_with_history
| llm
| StrOutputParser()
)
inputs = {"messages": [{"role": "user", "content": "Who owns MLflow?"}]}
print(chain_with_history.invoke(inputs))
# sample output:
# "1. Databricks\n2. Microsoft\n3. Google\n4. Amazon\n\nEnter your answer: 1\n\n
# Correct! MLflow is an open source project developed by Databricks. ...
# We automatically log the model and trace related artifacts
# A model with name `lc_model` is registered, we can load it back as a PyFunc model
model_name = "lc_model"
model_version = 1
loaded_model = mlflow.pyfunc.load_model(f"models:/{model_name}/{model_version}")
print(loaded_model.predict(inputs))
Tracing LangGraph
MLflow support automatic tracing for LangGraph, an open-source library from LangChain for building stateful, multi-actor applications with LLMs, used to create agent and multi-agent workflows. To enable auto-tracing for LangGraph, use the same mlflow.langchain.autolog() function.
from typing import Literal
import mlflow
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
# Enabling tracing for LangGraph (LangChain)
mlflow.langchain.autolog()
# Optional: Set a tracking URI and an experiment
mlflow.set_tracking_uri("http://localhost:5000")
mlflow.set_experiment("LangGraph")
@tool
def get_weather(city: Literal["nyc", "sf"]):
"""Use this to get weather information."""
if city == "nyc":
return "It might be cloudy in nyc"
elif city == "sf":
return "It's always sunny in sf"
llm = ChatOpenAI(model="gpt-4o-mini")
tools = [get_weather]
graph = create_react_agent(llm, tools)
# Invoke the graph
result = graph.invoke(
{"messages": [{"role": "user", "content": "what is the weather in sf?"}]}
)
Note
MLflow does not support other auto-logging features for LangGraph, such as automatic model logging. Only traces are logged for LangGraph.
How It Works
MLflow LangChain Autologging uses two ways to log traces and other artifacts. Tracing is made possible via the Callbacks framework of LangChain. Other artifacts are recorded by patching the invocation functions of the supported models. In typical scenarios, you don’t need to care about the internal implementation details, but this section provides a brief overview of how it works under the hood.
MLflow Tracing Callbacks
MlflowLangchainTracer is a callback handler that is injected into the langchain model inference process to log traces automatically. It starts a new span upon a set of actions of the chain such as on_chain_start, on_llm_start, and concludes it when the action is finished. Various metadata such as span type, action name, input, output, latency, are automatically recorded to the span.
Customize Callback
Sometimes you may want to customize what information is logged in the traces. You can achieve this by creating a custom callback handler that inherits from MlflowLangchainTracer. The following example demonstrates how to record an additional attribute to the span when a chat model starts running.
from mlflow.langchain.langchain_tracer import MlflowLangchainTracer
class CustomLangchainTracer(MlflowLangchainTracer):
# Override the handler functions to customize the behavior. The method signature is defined by LangChain Callbacks.
def on_chat_model_start(
self,
serialized: Dict[str, Any],
messages: List[List[BaseMessage]],
*,
run_id: UUID,
tags: Optional[List[str]] = None,
parent_run_id: Optional[UUID] = None,
metadata: Optional[Dict[str, Any]] = None,
name: Optional[str] = None,
**kwargs: Any,
):
"""Run when a chat model starts running."""
attributes = {
**kwargs,
**metadata,
# Add additional attribute to the span
"version": "1.0.0",
}
# Call the _start_span method at the end of the handler function to start a new span.
self._start_span(
span_name=name or self._assign_span_name(serialized, "chat model"),
parent_run_id=parent_run_id,
span_type=SpanType.CHAT_MODEL,
run_id=run_id,
inputs=messages,
attributes=kwargs,
)
Patch Functions for Logging Artifacts
Other artifacts such as models are logged by patching the invocation functions of the supported models to insert the logging call. MLflow patches the following functions:
invokebatchstreamget_relevant_documents(for retrievers)__call__(for Chains and AgentExecutors)ainvokeabatchastream
Warning
MLflow supports autologging for async functions (e.g., ainvoke, abatch, astream), however, the logging operation is not
asynchronous and may block the main thread. The invocation function itself is still not blocking and returns a coroutine object, but
the logging overhead may slow down the model inference process. Please be aware of this side effect when using async functions with autologging.
FAQ
If you encounter any issues with MLflow LangChain flavor, please also refer to FAQ <../index.html#faq>. If you still have questions, please feel free to open an issue in MLflow Github repo.
How to suppress the warning messages during autologging?
MLflow Langchain Autologging calls various logging functions and LangChain utilities under the hood. Some of them may
generate warning messages that are not critical to the autologging process. If you want to suppress these warning messages, pass silent=True to the mlflow.langchain.autolog() function.
import mlflow
mlflow.langchain.autolog(silent=True)
# No warning messages will be emitted from autologging
I can’t load the model logged by mlflow langchain autologging
There are a few type of models that MLflow LangChain autologging does not support native saving or loading.
Model contains langchain retrievers
LangChain retrievers are not supported by MLflow autologging. If your model contains a retriever, you will need to manually log the model using the
mlflow.langchain.log_modelAPI. As loading those models requires specifying loader_fn and persist_dir parameters, please check examples in retriever_chainCan’t pickle certain objects
For certain models that LangChain does not support native saving or loading, we will pickle the object when saving it. Due to this functionality, your cloudpickle version must be consistent between the saving and loading environments to ensure that object references resolve properly. For further guarantees of correct object representation, you should ensure that your environment has pydantic installed with at least version 2.
How to customize span names in the traces?
By default, MLflow creates span names based on the class name in LangChain, such as ChatOpenAI, RunnableLambda, etc. If you want to customize the span names, you can do the following:
Pass
nameparameter to the constructor of the LangChain class. This is useful when you want to set a specific name for a single component.Use
with_configmethod to set the name for the runnables. You can pass the"run_name"key to the config dictionary to set a name for a sub chain that contains multiple components.
import mlflow
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# Enable auto-tracing for LangChain
mlflow.langchain.autolog()
# Method 1: Pass `name` parameter to the constructor
model = ChatOpenAI(name="custom-llm", model="gpt-4o-mini")
# Method 2: Use `with_config` method to set the name for the runnables
runnable= (model | StrOutputParser()).with_config({"run_name": "custom-chain"})
runnable.invoke("Hi")
The above code will create a trace like the following:
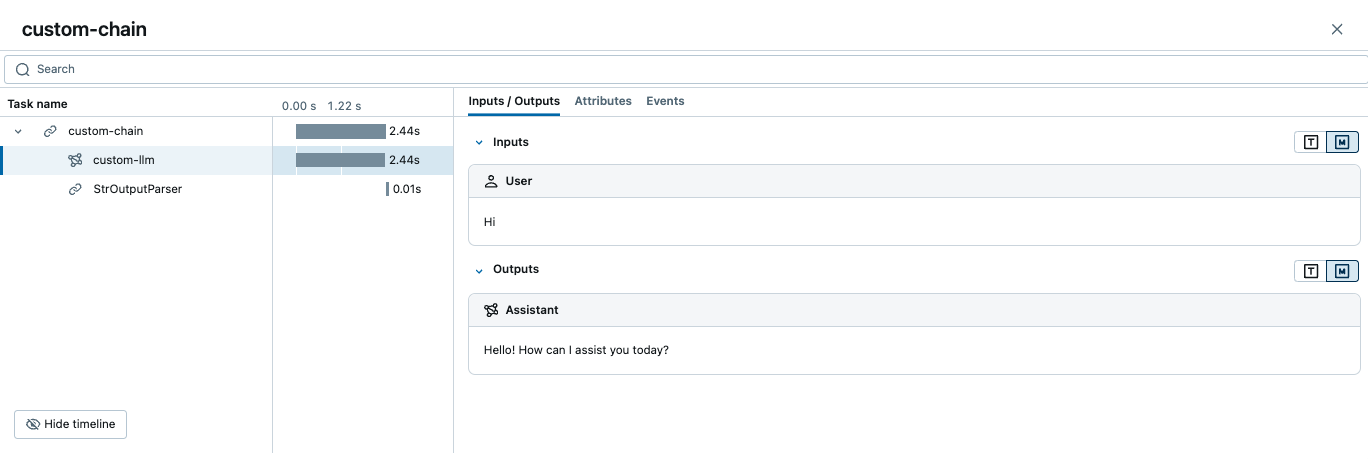
How to add extra metadata to a span?
You can record extra metadata to the span by passing the metadata parameter of the LangChain’s RunnableConfig dictionary, either to the constructor or at runtime.
import mlflow
from langchain_openai import ChatOpenAI
# Enable auto-tracing for LangChain
mlflow.langchain.autolog()
# Pass metadata to the constructor using `with_config` method
model = ChatOpenAI(model="gpt-4o-mini").with_config({"metadata": {"key1": "value1"}})
# Pass metadata at runtime using the `config` parameter
model.invoke("Hi", config={"metadata": {"key2": "value2"}})
The metadata can be accessed in the Attributes tab in the MLflow UI.