MLflow LangChain Flavor
Attention
The langchain flavor is under active development and is marked as Experimental. Public APIs are
subject to change, and new features may be added as the flavor evolves.
Welcome to the developer guide for the integration of LangChain with MLflow. This guide serves as a comprehensive resource for understanding and leveraging the combined capabilities of LangChain and MLflow in developing advanced language model applications.
LangChain is a versatile framework designed for building applications powered by language models. It excels in creating context-aware applications that utilize language models for reasoning and generating responses, enabling the development of sophisticated NLP applications.
LangGraph is a complementary agent-based framework from the creators of Langchain, supporting the creation of stateful agent and multi-agent GenAI applications. LangGraph utilizes LangChain in order to interface with GenAI agent components.
Why use MLflow with LangChain?
Aside from the benefits of using MLflow for managing and deploying machine learning models, the integration of LangChain with MLflow provides a number of benefits that are associated with using LangChain within the broader MLflow ecosystem.
Experiment Tracking
LangChain’s flexibility in experimenting with various agents, tools, and retrievers becomes even more powerful when paired with MLflow Tracking. This combination allows for rapid experimentation and iteration. You can effortlessly compare runs, making it easier to refine models and accelerate the journey from development to production deployment.
Dependency Management
Deploy your LangChain application with confidence, leveraging MLflow’s ability to manage and record code and environment dependencies automatically. You can also explicitly declare external resource dependencies, like the LLM serving endpoint or vector search index queried by your LangChain application. These dependencies are tracked by MLflow as model metadata, so that downstream serving systems can ensure authentication from your deployed LangChain application to these dependent resources just works.
These features ensure consistency between development and production environments, reducing deployment risks with less manual intervention.
MLflow Evaluate
MLflow Evaluate provides native capabilities within MLflow to evaluate language models. With this feature you can easily utilize automated evaluation algorithms on the results of your LangChain application’s inference results. This capability facilitates the efficient assessment of inference results from your LangChain application, ensuring robust performance analytics.
Observability
MLflow Tracing is a new feature of MLflow that allows you to trace how data flows through your LangChain chain/agents/etc. This feature provides a visual representation of the data flow, making it easier to understand the behavior of your LangChain application and identify potential bottlenecks or issues. With its powerful Automatic Tracing capability, you can instrument your LangChain application without any code change but just running mlflow.langchain.autolog() command once.
Automatic Logging
Autologging is a powerful one stop solution to achieve all the above benefits with just one line of code mlflow.langchain.autolog(). By enabling autologging, you can automatically log all the components of your LangChain application, including chains, agents, and retrievers, with minimal effort. This feature simplifies the process of tracking and managing your LangChain application, allowing you to focus on developing and improving your models. For more information on how to use this feature, refer to the MLflow LangChain Autologging Documentation.
Supported Elements in MLflow LangChain Integration
LangGraph Complied Graph (only supported via Model-from-Code)
LLMChain (deprecated, only support for
langchain<0.3.0)RetrievalQA (deprecated, only support for
langchain<0.3.0)
Warning
There is a known deserialization issue when logging chains or agents dependent upon LangChain components from the partner packages such as langchain-openai. If you log such models using the legacy serialization based logging, some components may be loaded from the respective langchain-community package instead of the partner package library, which can lead to unexpected behavior or import errors when executing your code.
To avoid this issue, we strongly recommend using the Model-from-Code method for logging such models. This method allows you to bypass the model serialization and robustly save the model definition.
Attention
Logging chains/agents that include ChatOpenAI and AzureChatOpenAI requires MLflow>=2.12.0 and LangChain>=0.0.307.
Overview of Chains, Agents, and Retrievers
Sequences of actions or steps hardcoded in code. Chains in LangChain combine various components like prompts, models, and output parsers to create a flow of processing steps.
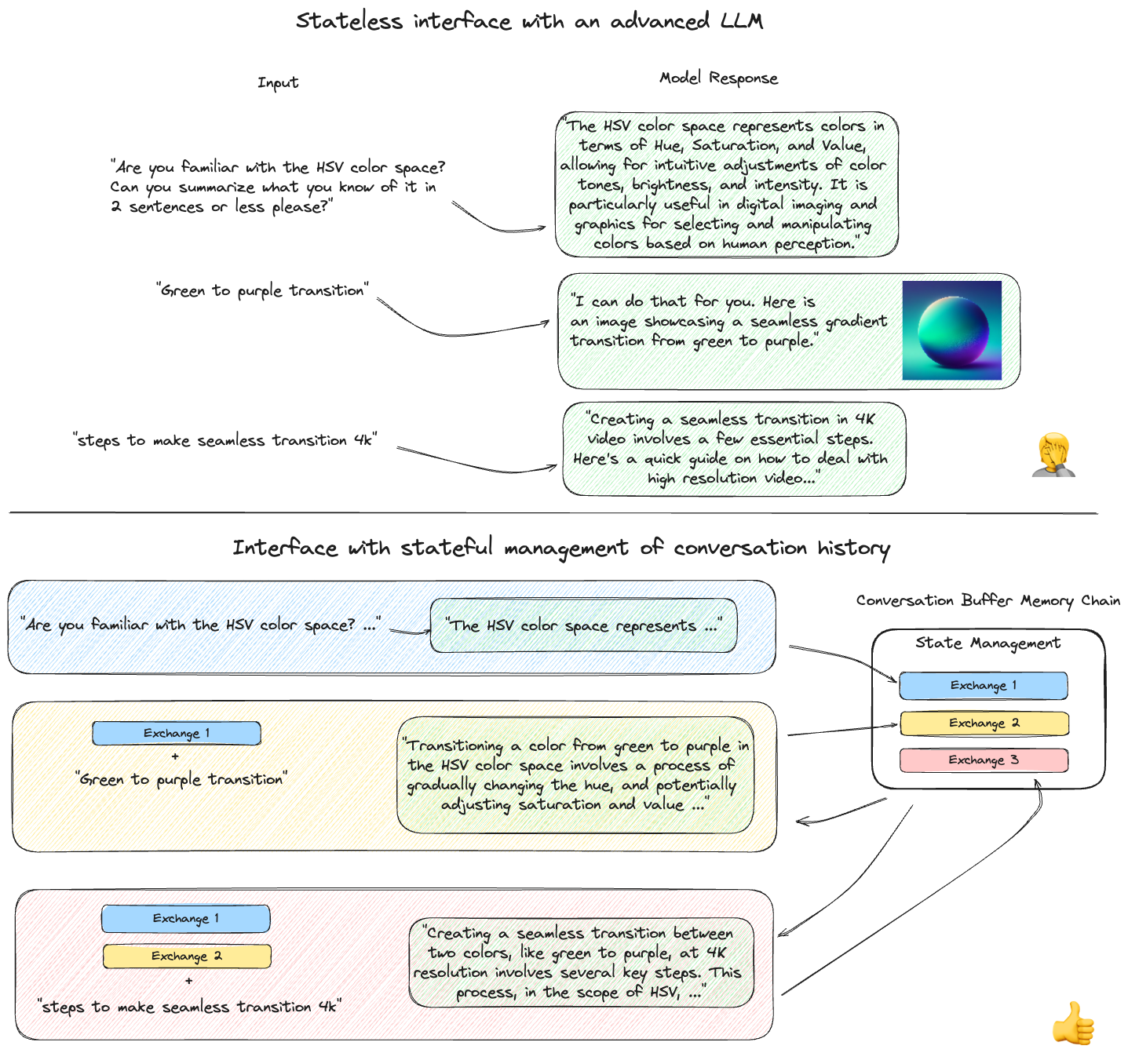
The figure below shows an example of interfacing directly with a SaaS LLM via API calls with no context to the history of the conversation in the top portion. The bottom portion shows the same queries being submitted to a LangChain chain that incorporates a conversation history state such that the entire conversation’s history is included with each subsequent input. Preserving conversational context in this manner is key to creating a “chat bot”.
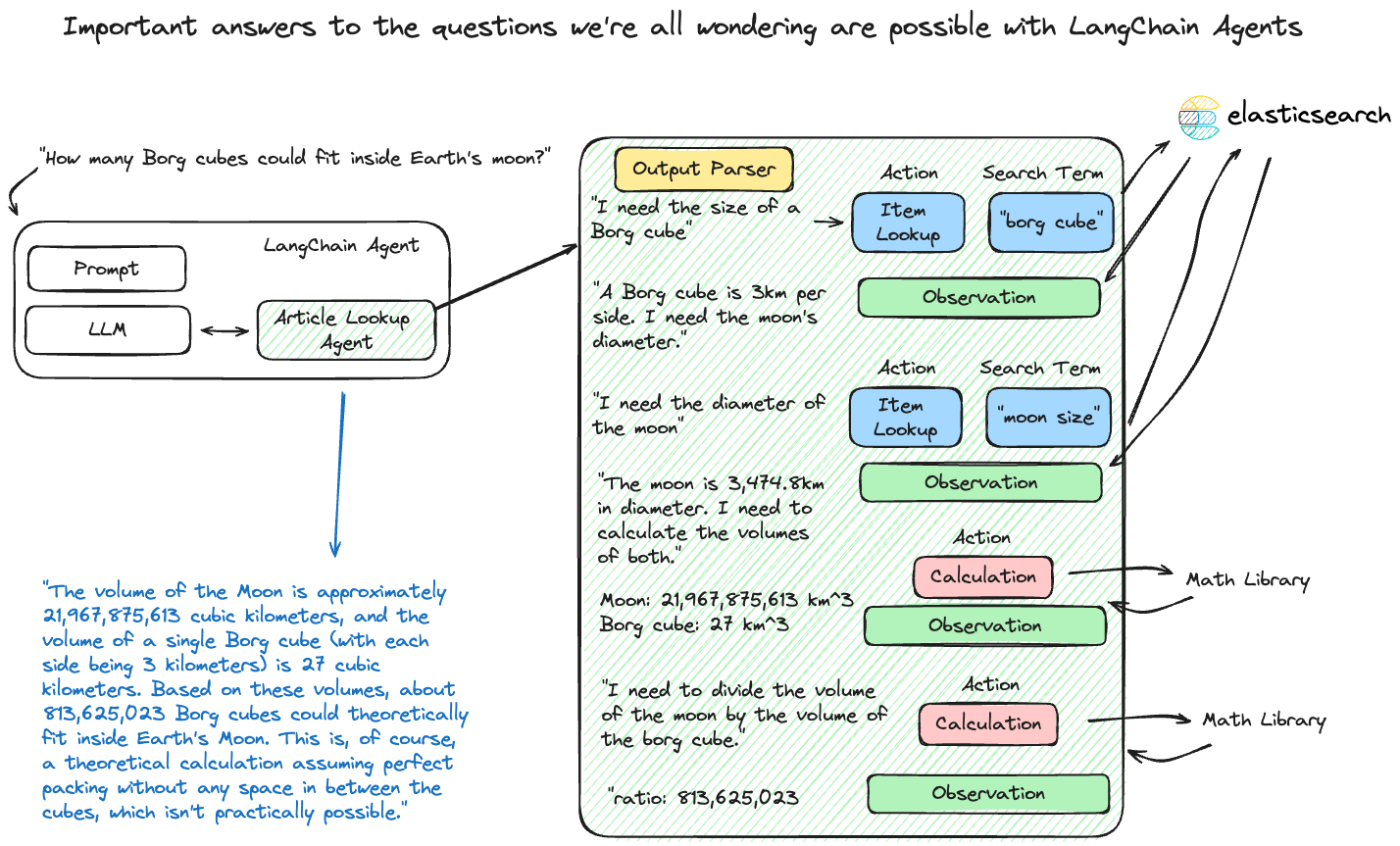
Dynamic constructs that use language models to choose a sequence of actions. Unlike chains, agents decide the order of actions based on inputs, tools available, and intermediate outcomes.
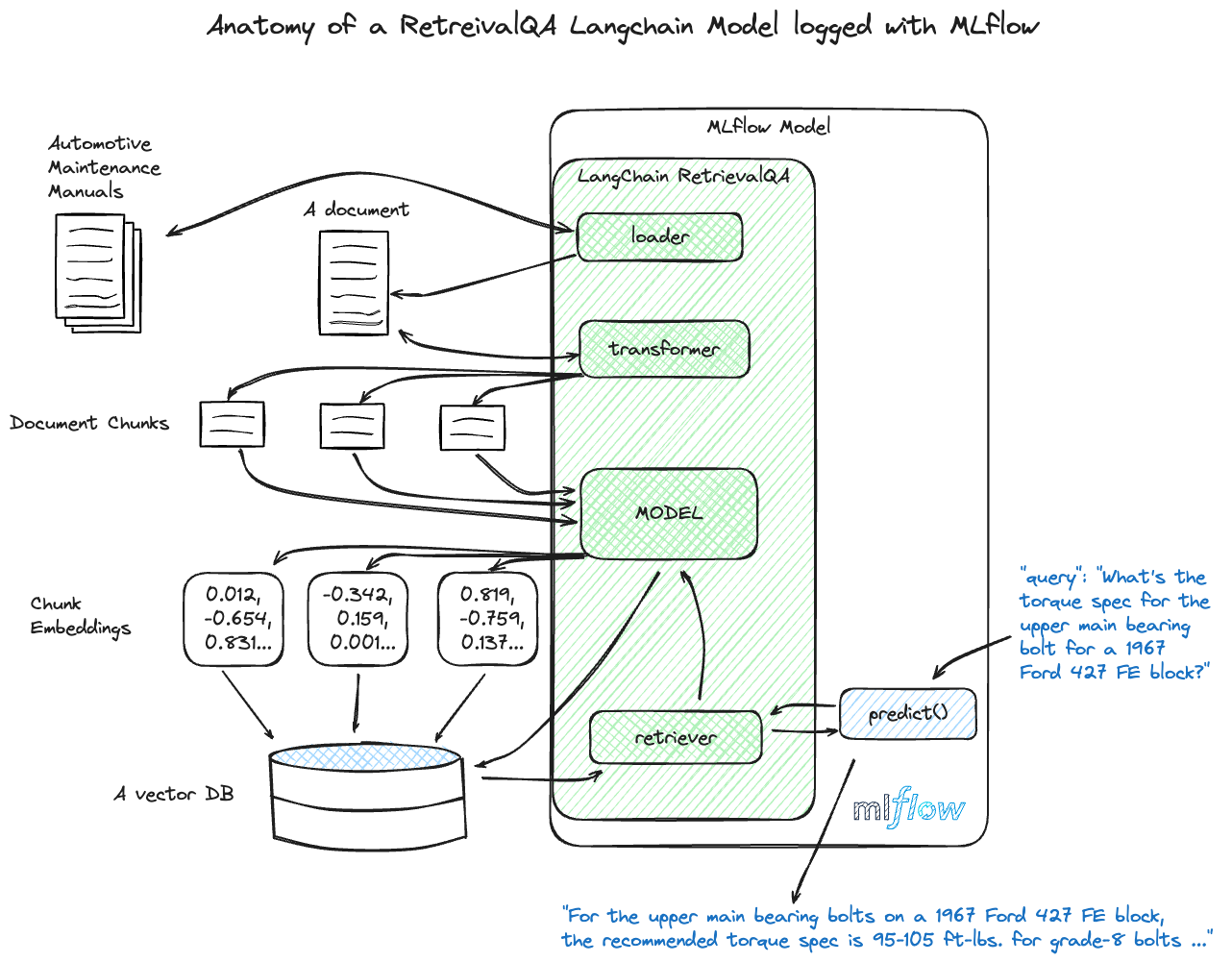
Components in RetrievalQA chains responsible for sourcing relevant documents or data. Retrievers are key in applications where LLMs need to reference specific external information for accurate responses.
Getting Started with the MLflow LangChain Flavor - Tutorials and Guides
Introductory Tutorial
In this introductory tutorial, you will learn the most fundamental components of LangChain and how to leverage the integration with MLflow to store, retrieve, and use a chain.
Advanced Tutorials
In these tutorials, you can learn about more complex usages of LangChain with MLflow. It is highly advised to read through the introductory tutorial prior to exploring these more advanced use cases.
Logging models from Code
Since MLflow 2.12.2, MLflow introduced the ability to log LangChain models directly from a code definition.
The feature provides several benefits to manage LangChain models:
Avoid Serialization Complication: File handles, sockets, external connections, dynamic references, lambda functions and system resources are unpicklable. Some LangChain components do not support native serialization, e.g.
RunnableLambda.No Pickling: Loading a pickle or cloudpickle file in a Python version that was different than the one used to serialize the object does not guarantee compatibility.
Readability: The serialized objects are often hardly readable by humans. Model-from-code allows you to review your model definition via code.
Refer to the Models From Code feature documentation for more information about this feature.
In order to use this feature, you will utilize the mlflow.models.set_model() API to define the chain that you would like to log as an MLflow model.
After having this set within your code that defines your chain, when logging your model, you will specify the path to the file that defines your chain.
The following example demonstrates how to log a simple chain with this method:
Define the chain in a separate Python file.**
Tip
If you are using Jupyter Notebook, you can use the %%writefile magic command to write the code cell directly to a file, without leaving the notebook to create it manually.
%%writefile chain.py import os from operator import itemgetter from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import PromptTemplate from langchain_core.runnables import RunnableLambda from langchain_openai import OpenAI import mlflow mlflow.set_experiment("Homework Helper") mlflow.langchain.autolog() prompt = PromptTemplate( template="You are a helpful tutor that evaluates my homework assignments and provides suggestions on areas for me to study further." " Here is the question: {question} and my answer which I got wrong: {answer}", input_variables=["question", "answer"], ) def get_question(input): default = "What is your name?" if isinstance(input_data[0], dict): return input_data[0].get("content").get("question", default) return default def get_answer(input): default = "My name is Bobo" if isinstance(input_data[0], dict): return input_data[0].get("content").get("answer", default) return default model = OpenAI(temperature=0.95) chain = ( { "question": itemgetter("messages") | RunnableLambda(get_question), "answer": itemgetter("messages") | RunnableLambda(get_answer), } | prompt | model | StrOutputParser() ) mlflow.models.set_model(chain)
Then from the main notebook, log the model via supplying the path to the file that defines the chain:
from pprint import pprint import mlflow chain_path = "chain.py" with mlflow.start_run(): info = mlflow.langchain.log_model(lc_model=chain_path, artifact_path="chain")
The model defined in
chain.pyis now logged to MLflow. You can load the model back and run inference:# Load the model and run inference homework_chain = mlflow.langchain.load_model(model_uri=info.model_uri) exam_question = { "messages": [ { "role": "user", "content": { "question": "What is the primary function of control rods in a nuclear reactor?", "answer": "To stir the primary coolant so that the neutrons are mixed well.", }, }, ] } response = homework_chain.invoke(exam_question) pprint(response)
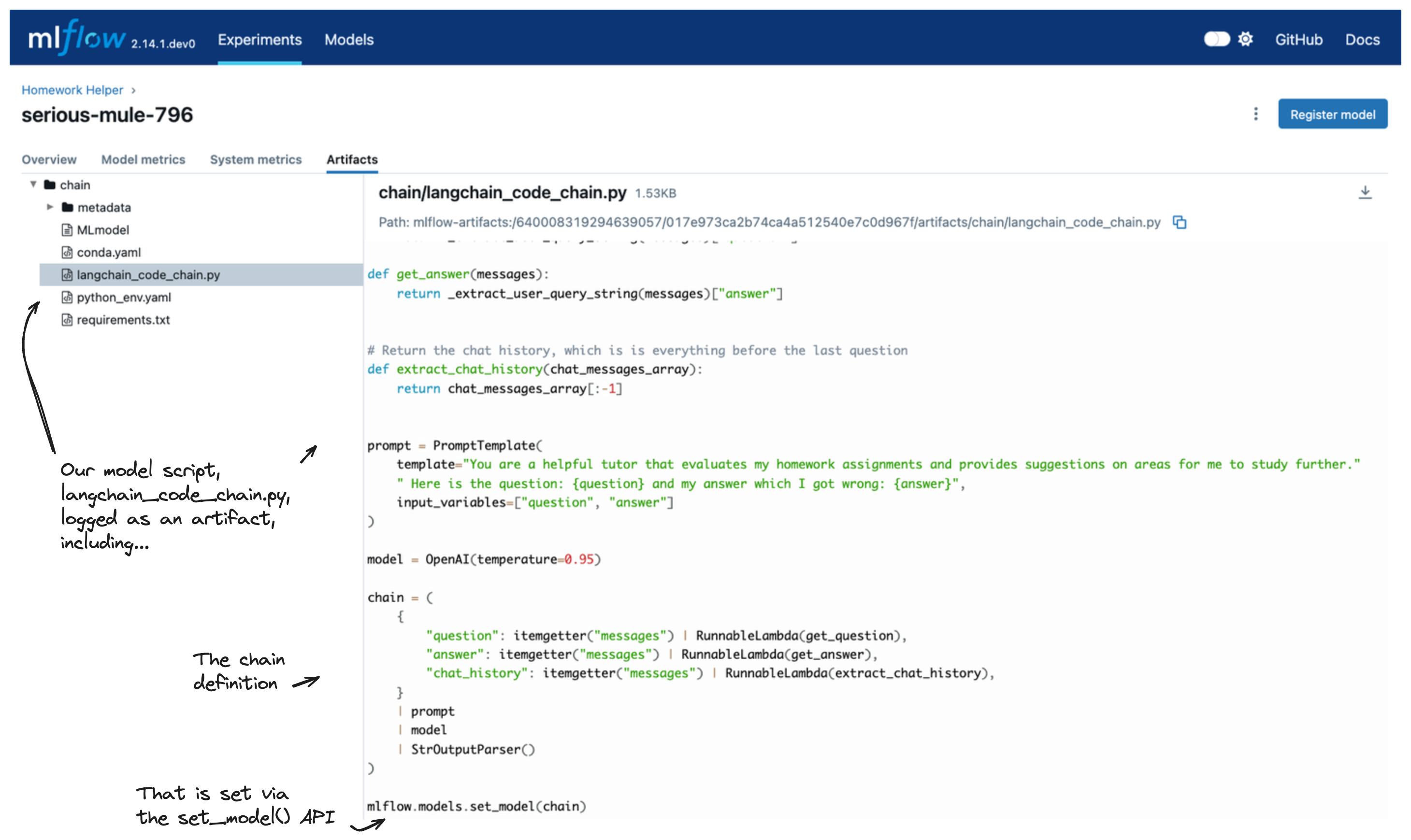
You can see the model is logged as a code on MLflow UI:
Warning
When logging models from code, make sure that your code does not contain any sensitive information, such as API keys, passwords, or other confidential data. The code will be stored in plain text in the MLflow model artifact, and anyone with access to the artifact will be able to view the code.
Detailed Documentation
To learn more about the details of the MLflow LangChain flavor, read the detailed guide below.
View the Comprehensive GuideFAQ
I can’t load my chain!
Allowing for Dangerous Deserialization: Pickle opt-in logic in LangChain will prevent components from being loaded via MLflow. You might see an error like this:
ValueError: This code relies on the pickle module. You will need to set allow_dangerous_deserialization=True if you want to opt-in to allow deserialization of data using pickle. Data can be compromised by a malicious actor if not handled properly to include a malicious payload that when deserialized with pickle can execute arbitrary code on your machine.
A change within LangChain that forces users to opt-in to pickle deserialization can create some issues with loading chains, vector stores, retrievers, and agents that have been logged using MLflow. Because the option is not exposed per component to set this argument on the loader function, you will need to ensure that you are setting this option directly within the defined loader function when logging the model. LangChain components that do not set this value will be saved without issue, but a
ValueErrorwill be raised when loading if unset.To fix this, simply re-log your model, specifying the option
allow_dangerous_deserialization=Truein your defined loader function. See the tutorial for LangChain retrievers for an example of specifying this option when logging aFAISSvector store instance within aloader_fndeclaration.
I can’t save my chain, agent, or retriever with MLflow.
Tip
If you’re encountering issues with logging or saving LangChain components with MLflow, see the models from code feature documentation to determine if logging your model from a script file provides a simpler and more robust logging solution!
Serialization Challenges with Cloudpickle: Serialization with cloudpickle can encounter limitations depending on the complexity of the objects.
Some objects, especially those with intricate internal states or dependencies on external system resources, are not inherently pickleable. This limitation arises because serialization essentially requires converting an object to a byte stream, which can be complex for objects tightly coupled with system states or those having external I/O operations. Try upgrading PyDantic to 2.x version to resolve this issue.
Verifying Native Serialization Support: Ensure that the langchain object (chain, agent, or retriever) is serializable natively using langchain APIs if saving or logging with MLflow doesn’t work.
Due to their complex structures, not all langchain components are readily serializable. If native serialization is not supported and MLflow doesn’t support saving the model, you can file an issue in the LangChain repository or ask for guidance in the LangChain Discussions board.
Keeping Up with New Features in MLflow: MLflow might not immediately support the latest LangChain features immediately.
If a new feature is not supported in MLflow, consider filing a feature request on the MLflow GitHub issues page. With the rapid pace of changes in libraries that are in heavy active development (such as LangChain’s release velocity), breaking changes, API refactoring, and fundamental functionality support for even existing features can cause integration issues. If there is a chain, agent, retriever, or any future structure within LangChain that you’d like to see supported, please let us know!
I’m getting an AttributeError when saving my model
Handling Dependency Installation in LangChain and MLflow: LangChain and MLflow do not automatically install all dependencies.
Other packages that might be required for specific agents, retrievers, or tools may need to be explicitly defined when saving or logging your model. If your model relies on these external component libraries (particularly for tools) that not included in the standard LangChain package, these dependencies will not be automatically logged as part of the model at all times (see below for guidance on how to include them).
Declaring Extra Dependencies: Use the
extra_pip_requirementsparameter when saving and logging.When saving or logging your model that contains external dependencies that are not part of the core langchain installation, you will need these additional dependencies. The model flavor contains two options for declaring these dependencies:
extra_pip_requirementsandpip_requirements. While specifyingpip_requirementsis entirely valid, we recommend usingextra_pip_requirementsas it does not rely on defining all of the core dependent packages that are required to use the langchain model for inference (the other core dependencies will be inferred automatically).
How can I use a streaming API with LangChain?
Streaming with LangChain Models: Ensure that the LangChain model supports a streaming response and use an MLflow version >= 2.12.2.
As of the MLflow 2.12.2 release, LangChain models that support streaming responses that have been saved using MLflow 2.12.2 (or higher) can be loaded and used for streamable inference using the
predict_streamAPI. Ensure that you are consuming the return type correctly, as the return from these models is aGeneratorobject. To learn more, refer to the predict_stream guide.
How can I log an agent built with LangGraph to MLflow?
The LangGraph integration with MLflow is designed to utilize the Models From Code feature in MLflow to broaden and simplify the support of agent serialization.
To log a LangGraph agent, you can define your agent code within a script, as shown below, saved to a file langgraph.py:
from typing import Literal
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
import mlflow
@tool
def get_weather(city: Literal["seattle", "sf"]):
"""Use this to get weather information."""
if city == "seattle":
return "It's probably raining. Again."
elif city == "sf":
return "It's always sunny in sf"
llm = ChatOpenAI()
tools = [get_weather]
graph = create_react_agent(llm, tools)
# specify the Agent as the model interface to be loaded when executing the script
mlflow.models.set_model(graph)
When you’re ready to log this agent script definition to MLflow, you can refer to this saved script directly when defining the model:
import mlflow
input_example = {
"messages": [{"role": "user", "content": "what is the weather in seattle today?"}]
}
with mlflow.start_run():
model_info = mlflow.langchain.log_model(
lc_model="./langgraph.py", # specify the path to the LangGraph agent script definition
artifact_path="langgraph",
input_example=input_example,
)
When the agent is loaded from MLflow, the script will be executed and the defined agent will be made available for use for invocation.
The agent can be loaded and used for inference as follows:
agent = mlflow.langchain.load_model(model_info.model_uri)
query = {
"messages": [
{
"role": "user",
"content": "Should I bring an umbrella today when I go to work in San Francisco?",
}
]
}
agent.invoke(query)
How can I evaluate a LangGraph Agent?
The mlflow.evaluate function provides a robust way to evaluate model performance.
LangGraph agents, especially those with chat functionality, can return multiple messages in one
inference call. Given mlflow.evaluate performs naive comparisons between raw predictions and a specified
ground truth value, it is the user’s responsibility to reconcile potential differences prediction output
and ground truth.
Often, the best approach is to use a custom function to process the response. Below we provide an example of a custom function that extracts the last chat message from a LangGraph model. This function is then used in mlflow.evaluate to return a single string response, which can be compared to the “ground_truth” column.
import mlflow
import pandas as pd
from typing import List
# Note that we assume the `model_uri` variable is present
# Also note that registering and loading the model is optional and you
# can simply leverage your langgraph object in the custom function.
loaded_model = mlflow.langchain.load_model(model_uri)
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"ground_truth": [
"MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle. It was developed by Databricks, a company that specializes in big data and machine learning solutions. MLflow is designed to address the challenges that data scientists and machine learning engineers face when developing, training, and deploying machine learning models.",
"Apache Spark is an open-source, distributed computing system designed for big data processing and analytics. It was developed in response to limitations of the Hadoop MapReduce computing model, offering improvements in speed and ease of use. Spark provides libraries for various tasks such as data ingestion, processing, and analysis through its components like Spark SQL for structured data, Spark Streaming for real-time data processing, and MLlib for machine learning tasks",
],
}
)
def custom_langgraph_wrapper(inputs: pd.DataFrame) -> List[str]:
"""Extract the predictions from a chat message sequence."""
answers = []
for content in inputs["inputs"]:
prediction = loaded_model.invoke(
{"messages": [{"role": "user", "content": content}]}
)
last_message_content = prediction["messages"][-1].content
answers.append(last_message_content)
return answers
with mlflow.start_run() as run:
results = mlflow.evaluate(
custom_langgraph_wrapper, # Pass our function defined above
data=eval_data,
targets="ground_truth",
model_type="question-answering",
extra_metrics=[
mlflow.metrics.latency(),
mlflow.metrics.genai.answer_correctness("openai:/gpt-4o"),
],
)
print(results.metrics)
{
"latency/mean": 1.8976624011993408,
"latency/variance": 0.10328687906900313,
"latency/p90": 2.1547686100006103,
"flesch_kincaid_grade_level/v1/mean": 12.1,
"flesch_kincaid_grade_level/v1/variance": 0.25,
"flesch_kincaid_grade_level/v1/p90": 12.5,
"ari_grade_level/v1/mean": 15.850000000000001,
"ari_grade_level/v1/variance": 0.06250000000000044,
"ari_grade_level/v1/p90": 16.05,
"exact_match/v1": 0.0,
"answer_correctness/v1/mean": 5.0,
"answer_correctness/v1/variance": 0.0,
"answer_correctness/v1/p90": 5.0,
}
For a complete example of a LangGraph model that works with this evaluation example, see the MLflow LangGraph blog.
How to control whether my input is converted to List[langchain.schema.BaseMessage] in PyFunc predict?
By default, MLflow converts chat request format input {"messages": [{"role": "user", "content": "some_question"}]} to
List[langchain.schema.BaseMessage] like [HumanMessage(content="some_question")] for certain model types.
To force the conversion, set the environment variable MLFLOW_CONVERT_MESSAGES_DICT_FOR_LANGCHAIN to True.
To disable this behavior, set the environment variable MLFLOW_CONVERT_MESSAGES_DICT_FOR_LANGCHAIN to False as demonstrated below:
import json
import mlflow
import os
from operator import itemgetter
from langchain.schema.runnable import RunnablePassthrough
model = RunnablePassthrough.assign(
problem=lambda x: x["messages"][-1]["content"]
) | itemgetter("problem")
input_example = {
"messages": [
{
"role": "user",
"content": "Hello",
}
]
}
# this model accepts the input_example
assert model.invoke(input_example) == "Hello"
# set this environment variable to avoid input conversion
os.environ["MLFLOW_CONVERT_MESSAGES_DICT_FOR_LANGCHAIN"] = "false"
with mlflow.start_run():
model_info = mlflow.langchain.log_model(model, "model", input_example=input_example)
pyfunc_model = mlflow.pyfunc.load_model(model_info.model_uri)
assert pyfunc_model.predict(input_example) == ["Hello"]